Corpus Description
In order to provide a firmer basis for the analysis of prosodic metrics, we decided to build an open multilingual prosodic database (OpenProDat), to be archived and distributed by the recently created Speech and Language Data Repository (SLDR) (http://www.sldr.org) under an open database license. The aim of this database is to collect, archive and distribute recordings and annotations of directly comparable data from a representative sample of different languages representing different prosodic typological characteristics.
Download
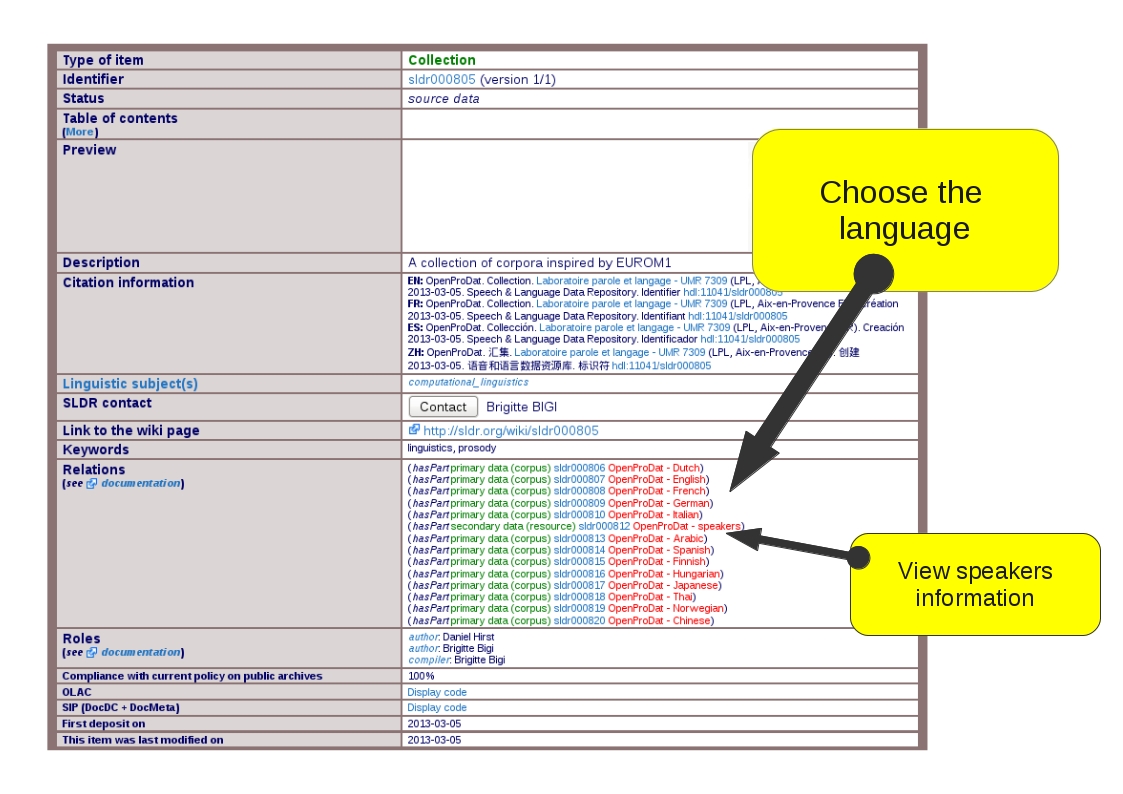
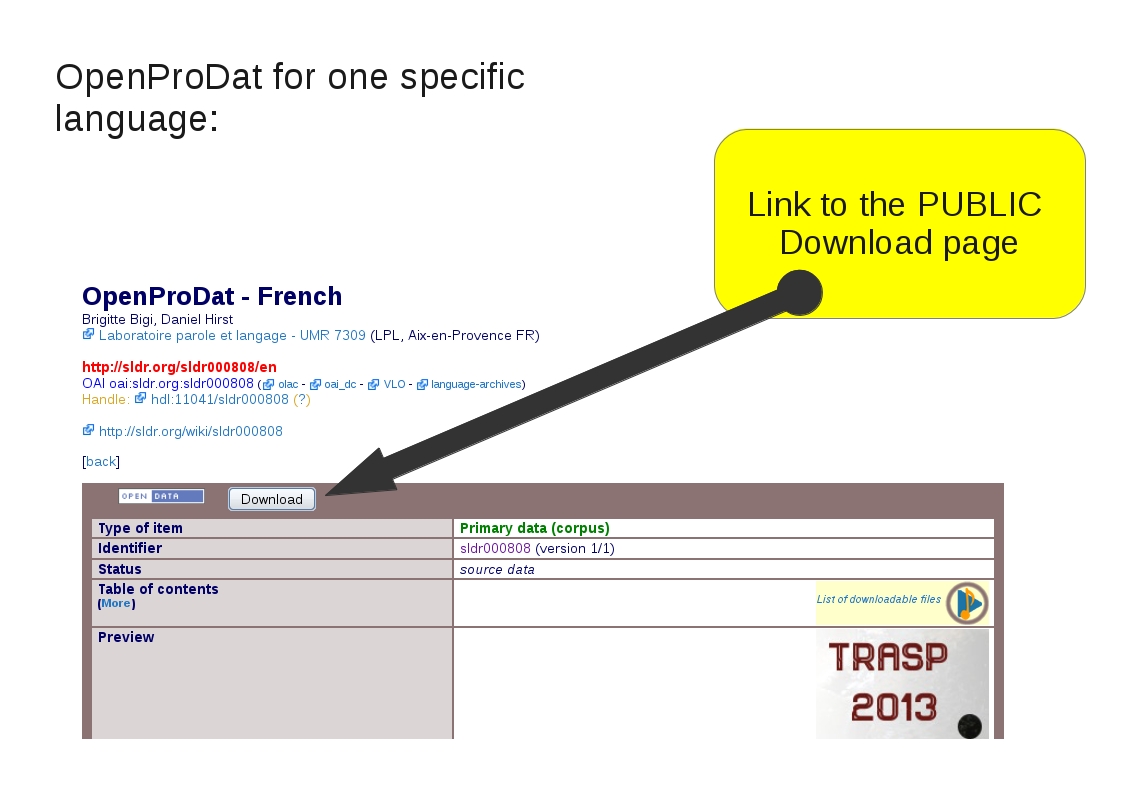
The corpus is hosted by SLDR. The corpus is publicaly available.
New recordings will be added regularly.
Help
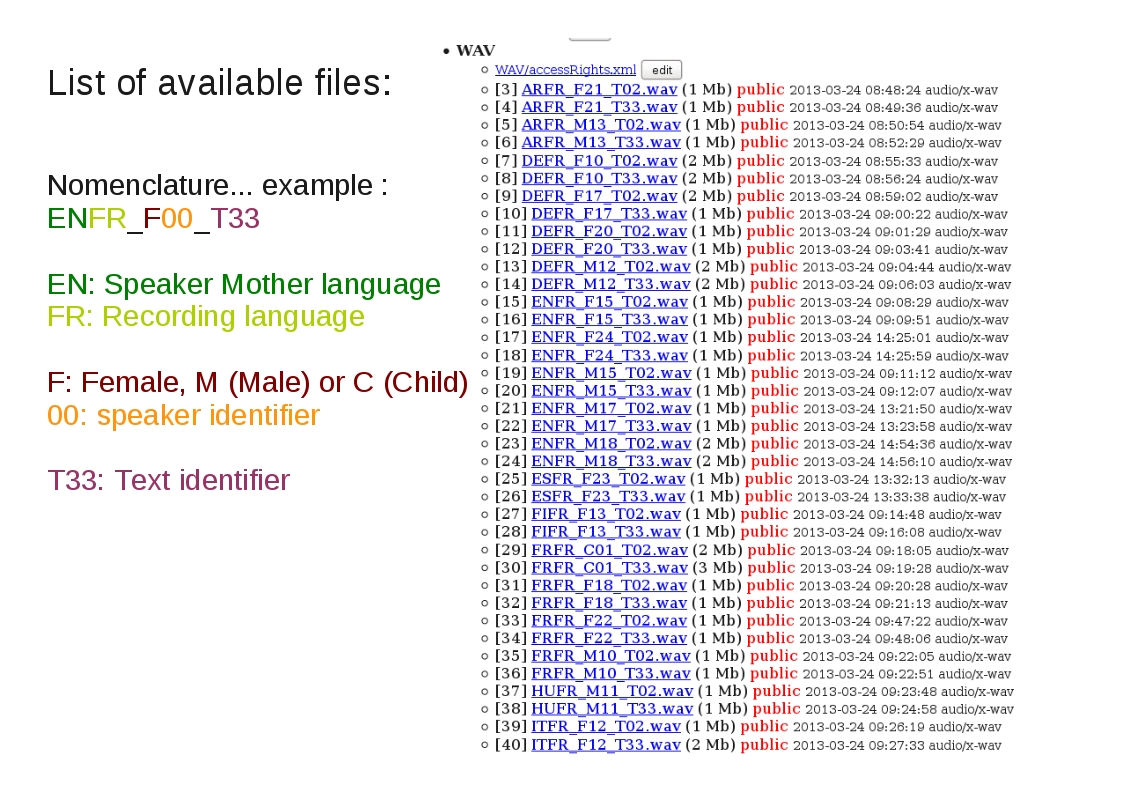
Some transcriptions are also available as textgrid files:
