
 |
Formal models for annotations |
The multiplication of annotation schemes (each project proposing its own) and that of coding formats (one per annotation tool) is a severe limitation for interoperability. We propose to use a more general description level, representing the annotation scheme by means of typed feature structures. Such a representation is independent from coding languages and tools. It is then used in the context of a strict conversion towards an XML schema: TFS are directly coded into UML structures which are automatically translated into an XML schema. Multimodal data are then integrated in an XML format following this schema.
Building annotated corpora requires first a precise definition of the linguistic information to be represented (an annotation scheme). Each domain has its specific needs. Linguistic information needs in one hand to be structured (when necessary) in terms of constituency and on the other hand in terms of types. Both representations are hierarchical. In a formal perspective, this kind of requirements are directly represented with typed feature structures (TFS). In this project, we proposed TFS to represent a precise level of annotation for the different domains and modalities: phonetics, phonology, prosody, morphology, syntax, discourse and gesture.
Building annotated corpora requires secondly a specification of the format used to concretely encode this information (what we call the coding scheme). We can represent a TFS description by a set of UML class diagrams by means of simple mapping rules. Finally, the process generates an XML schema for each domain (i.e. each TFS).
 |
CID Corpus |
|
CID - Corpus of Interactional Data is an audio-visual recording of 8 hours of conversational French dialogues (1 hour of recording per session). Many annotations are now available for research purposes. |
 |
Softwares |
Automatic Syllable Annotation Tool
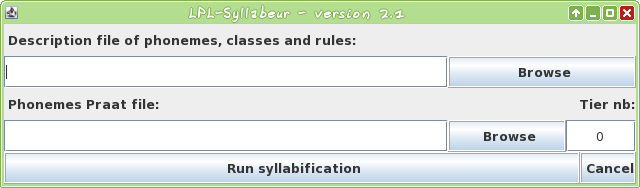
An automatic syllable boundaries detection system was created to label CID. The syllabification is performed from phonemes sequences. The algorithm consists in determining boundaries into phonemes between two vowels dealing with their phoneme classes. Click Here for a description.
The proposed system is implemented in java 1.6. The input phonemes are encoded with SAMPA (Speech Assessment Methods Phonetic Alphabet) in a TextGrid file The program produces syllables in a TextGrid file. This program is under GPL licence.
A configuration file can be easily adapted to other phoneme encodings and/or other rules. The, it can be used with another language.
Here is an input/output example:
| Transcription: | il expliquait pas vraiment ce qu'il y avait dedans | Phonemes: | i l e k s p l i k e p ɑ v ɾ e m ɑ~ s k i j ɑ v e d ɑ~ |
| Syllables: | i . lek . spli . ke . pɑ . vɾe . mɑ~ . ski . jɑ . ve . dɑ~ |
Download the LPL-Syllabeur-v2.1.jar
How to use it:
- Click on the jar file to extract files. You will need to extract the file "LPL-Syllabeur-v2.1/descr/FR-CID.txt", or another description file in the same directory, and, you can also extract some examples, etc...
- Then, double click on the jar file to execute it! (or "java -jar LPL-Syllabeur-v2.1.jar")
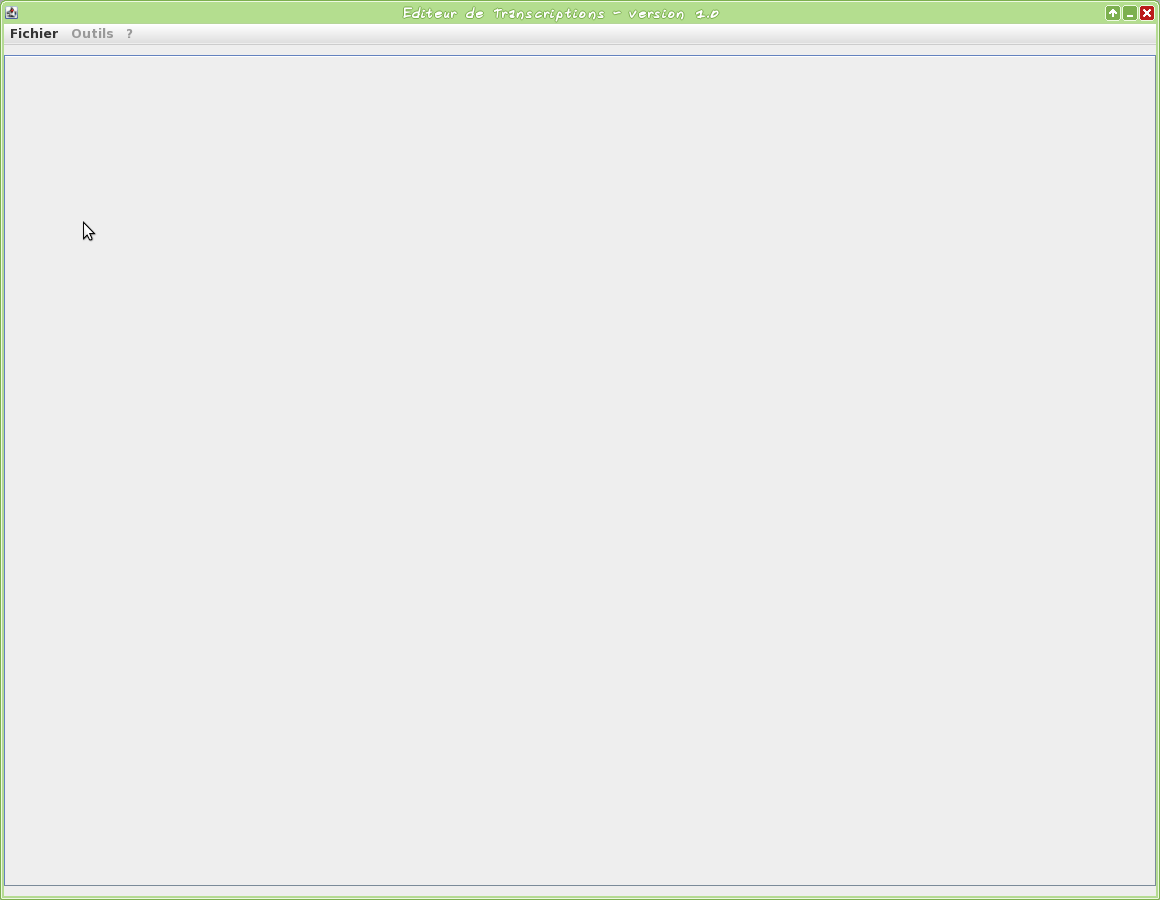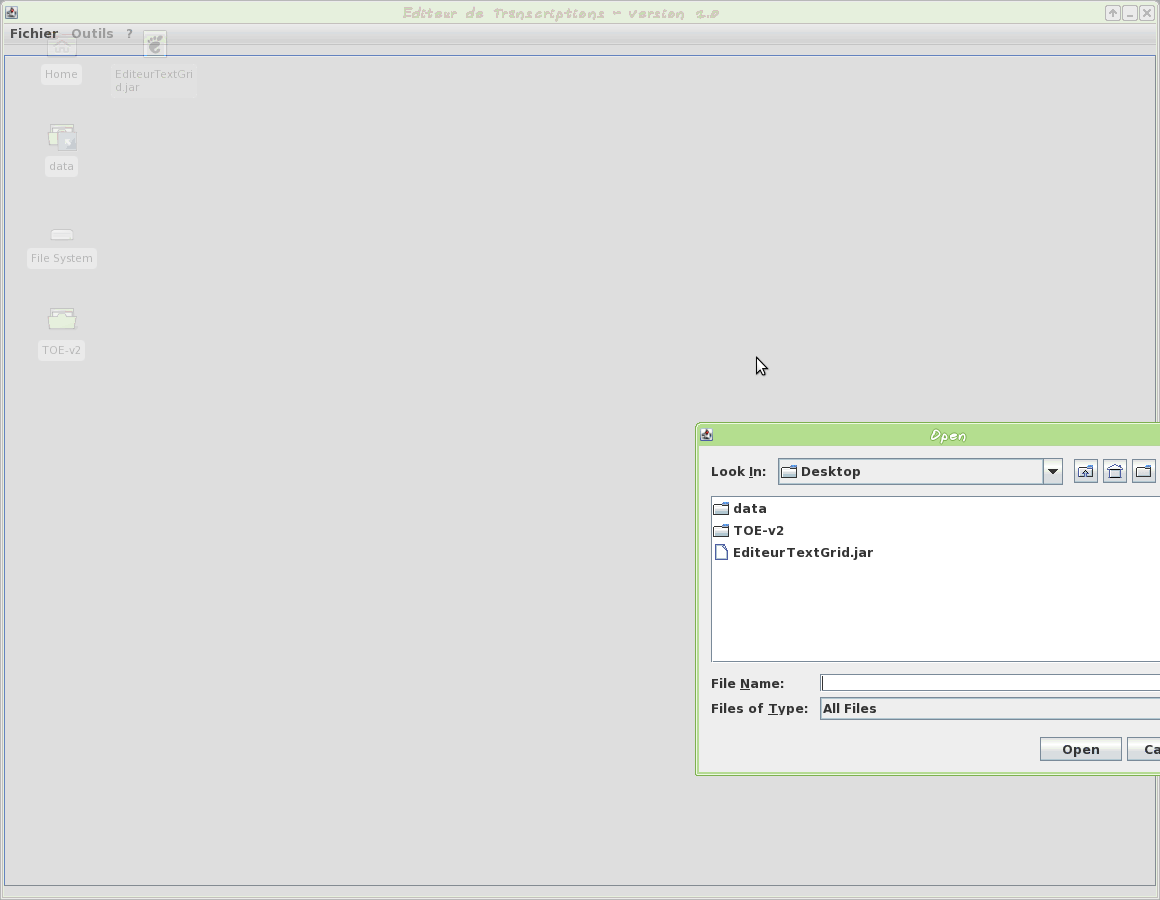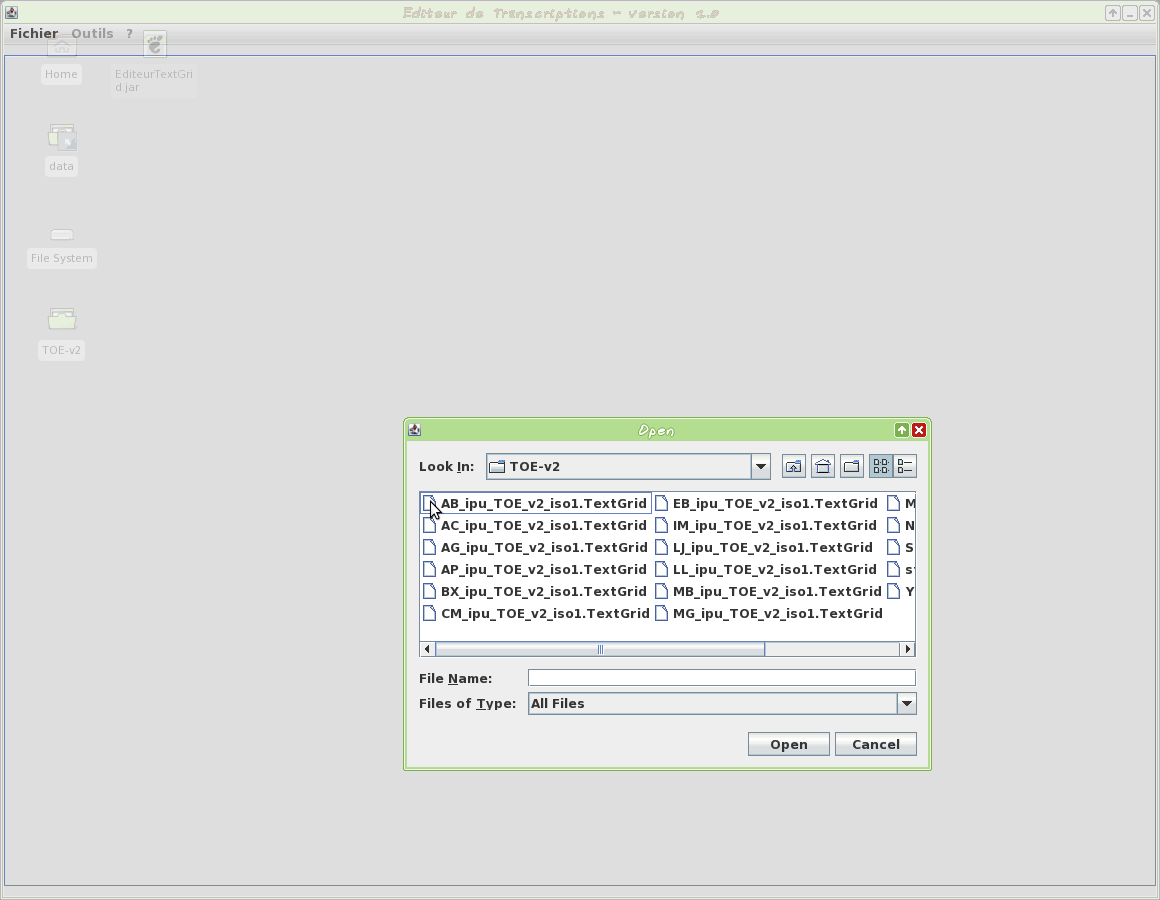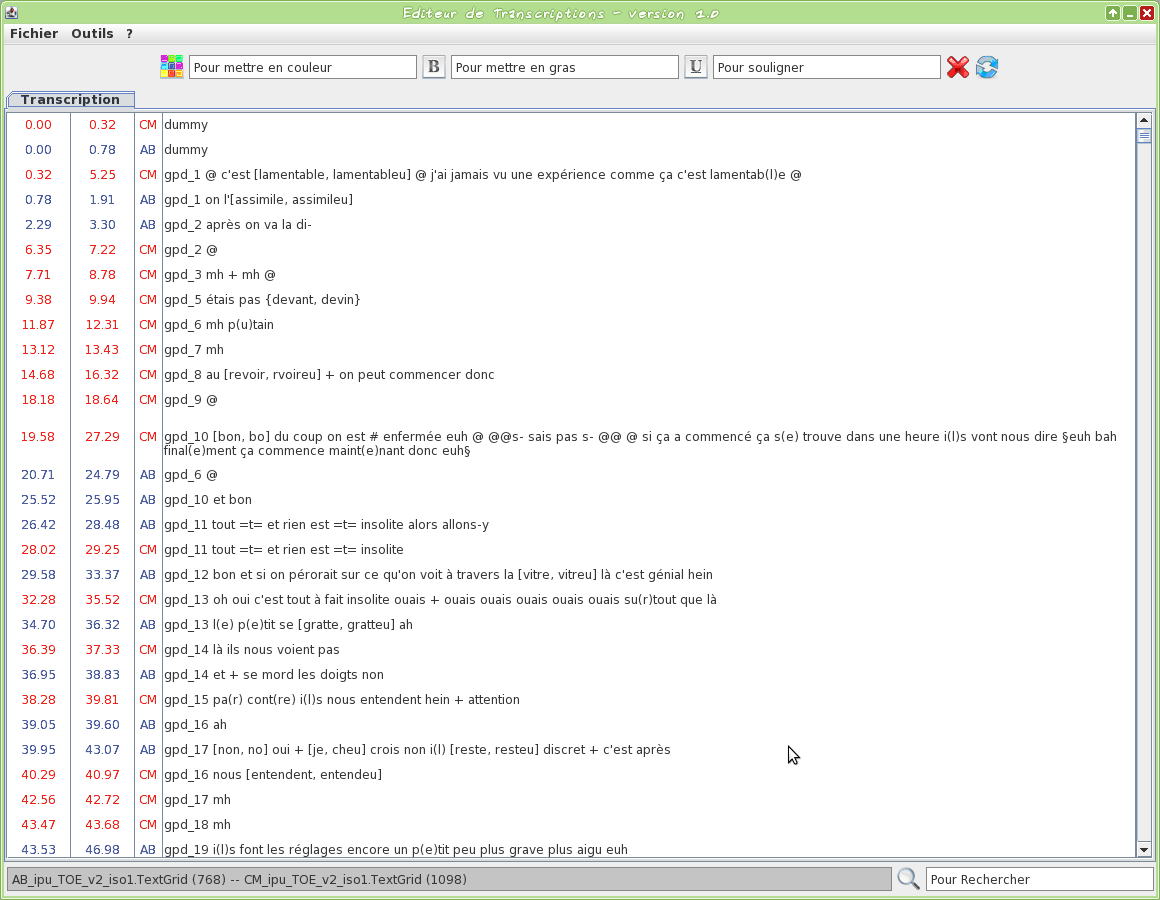
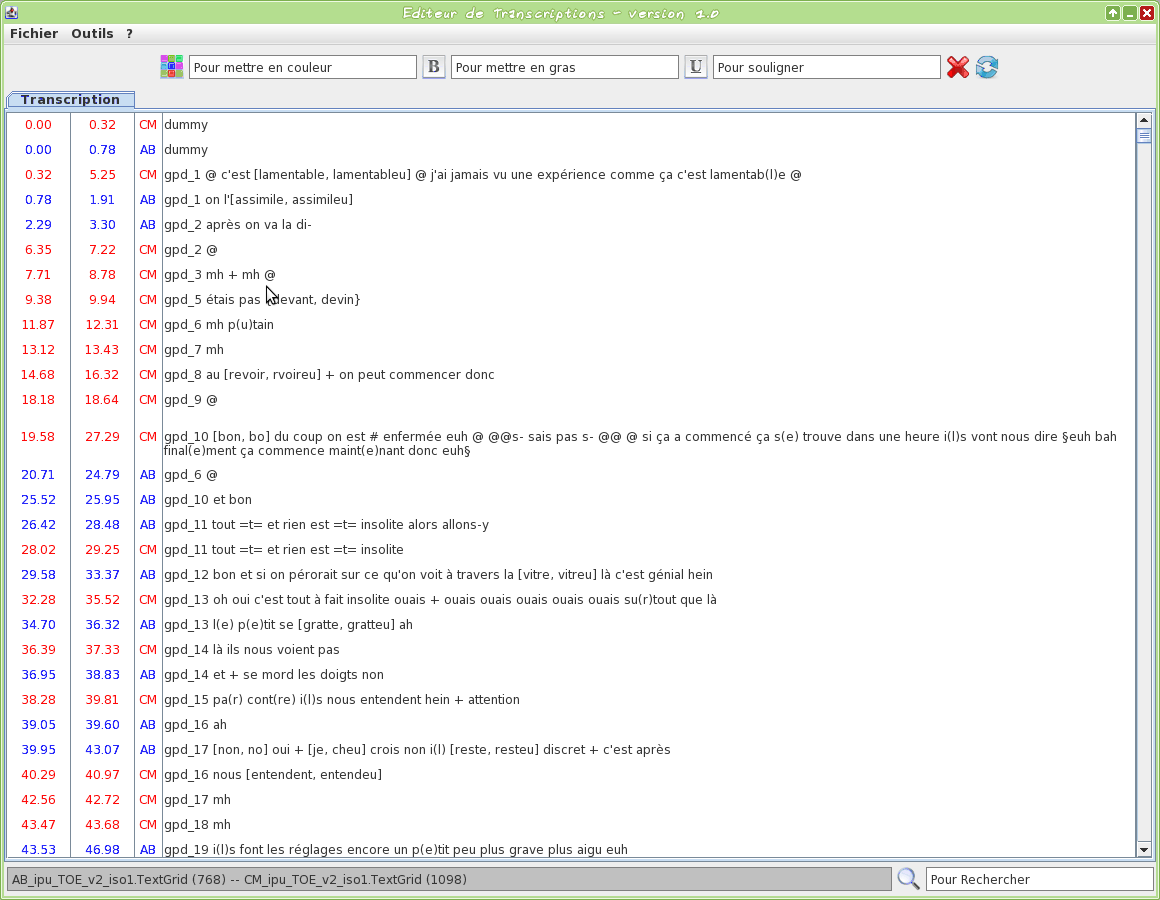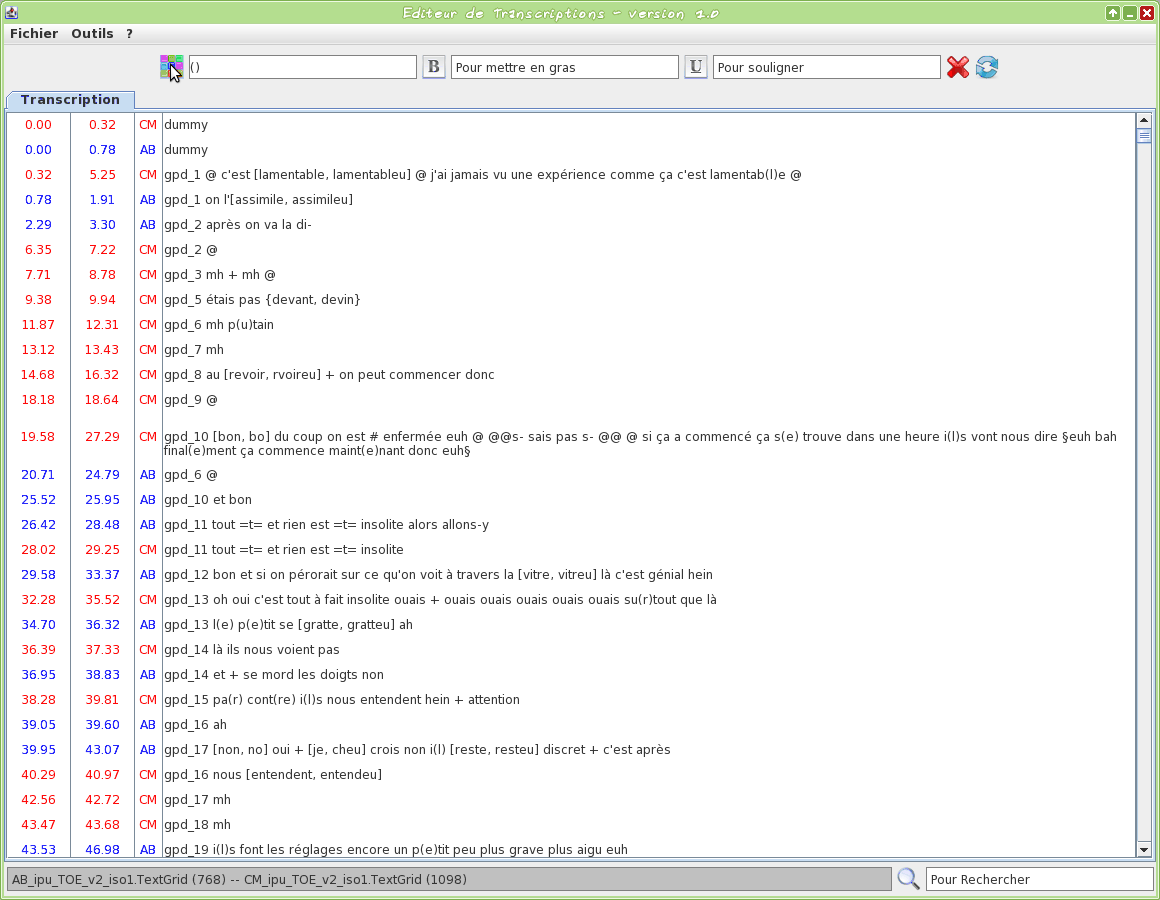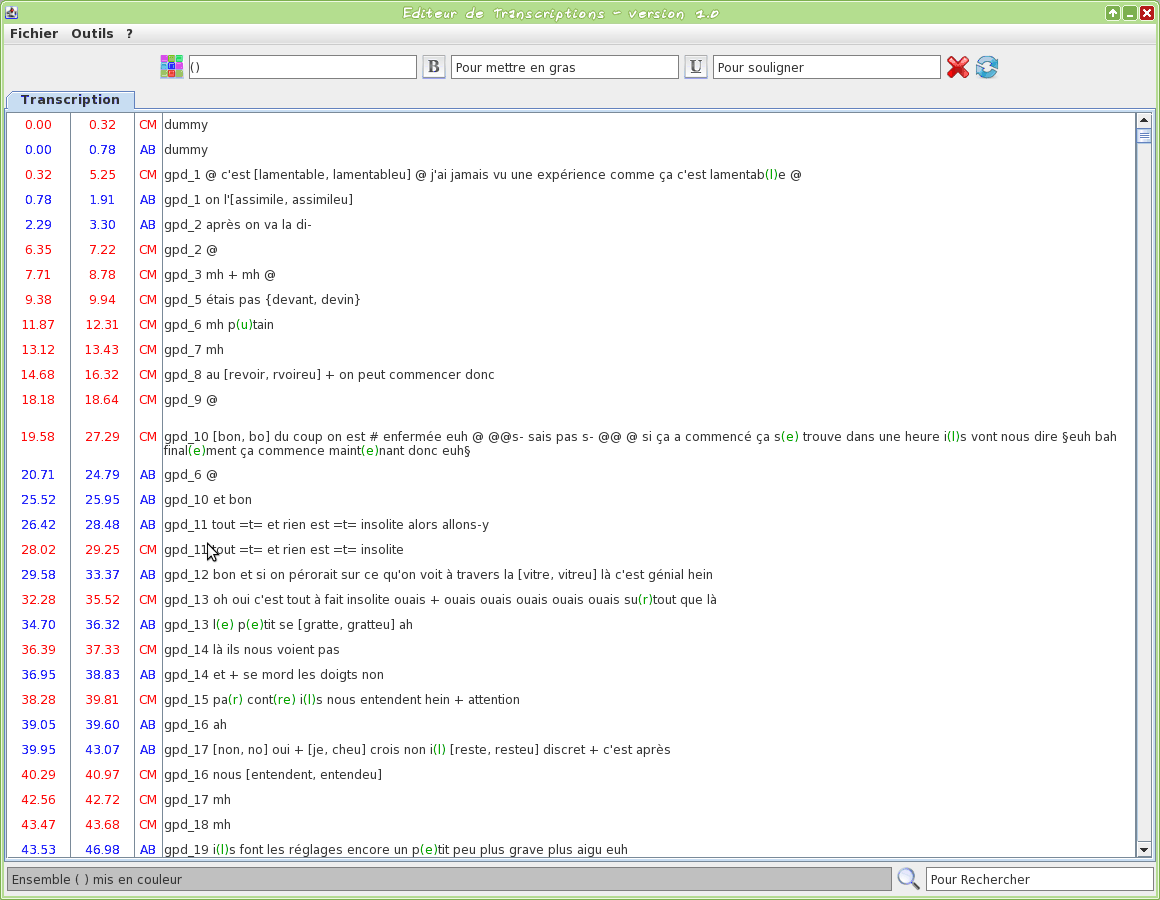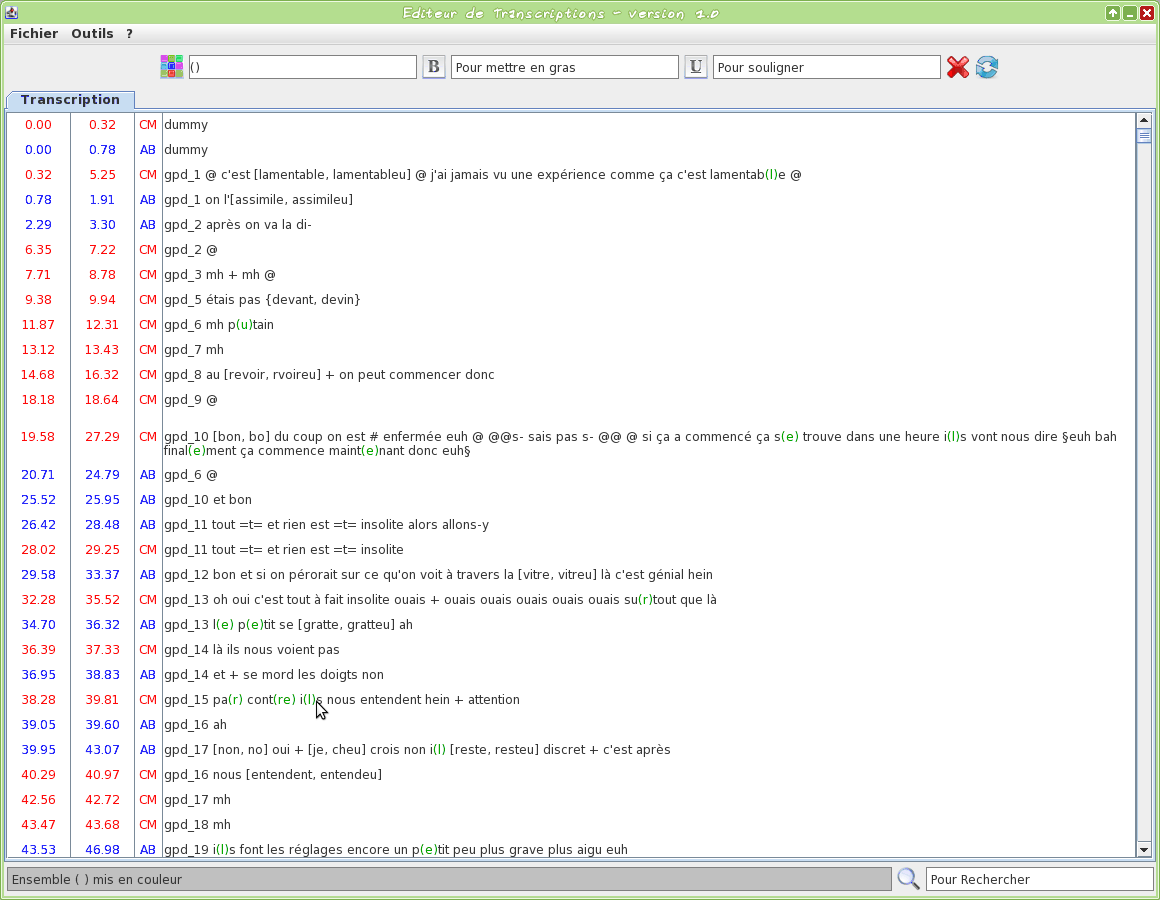
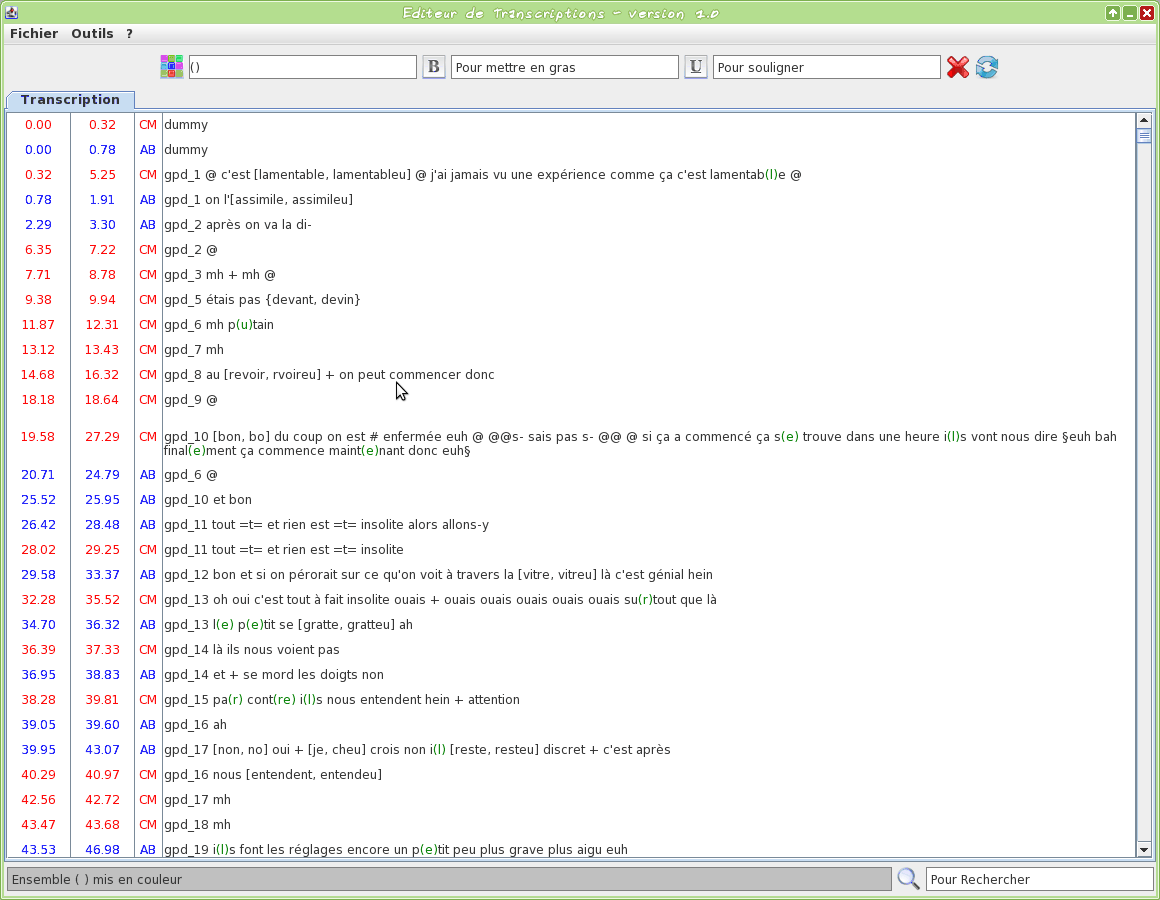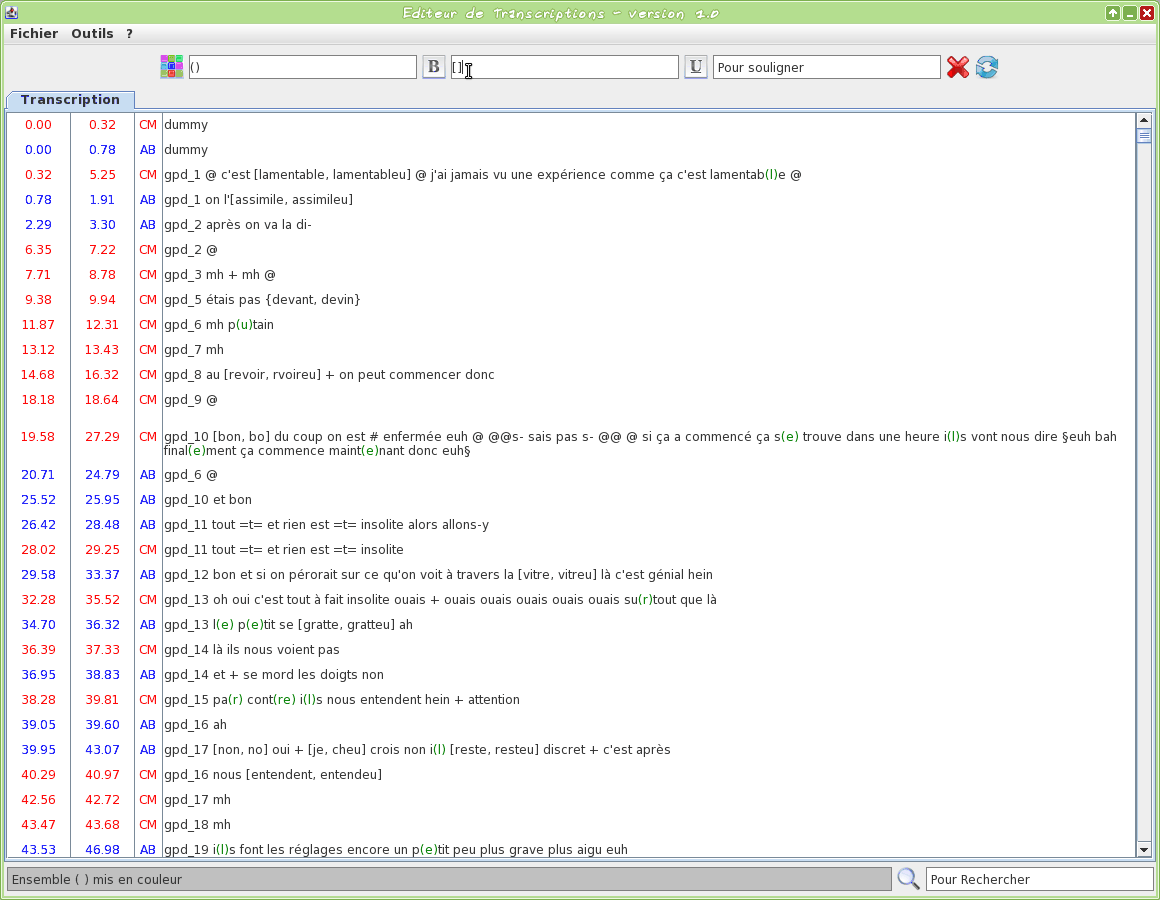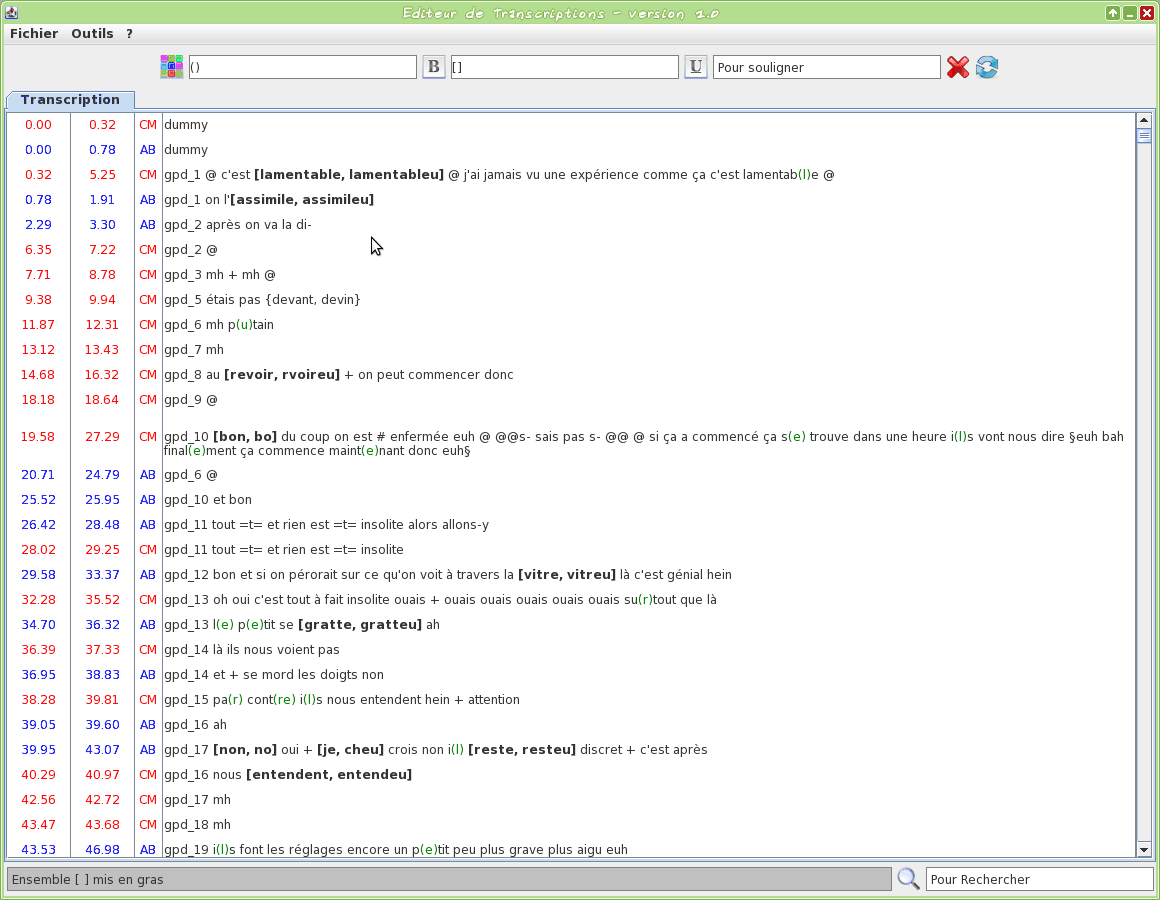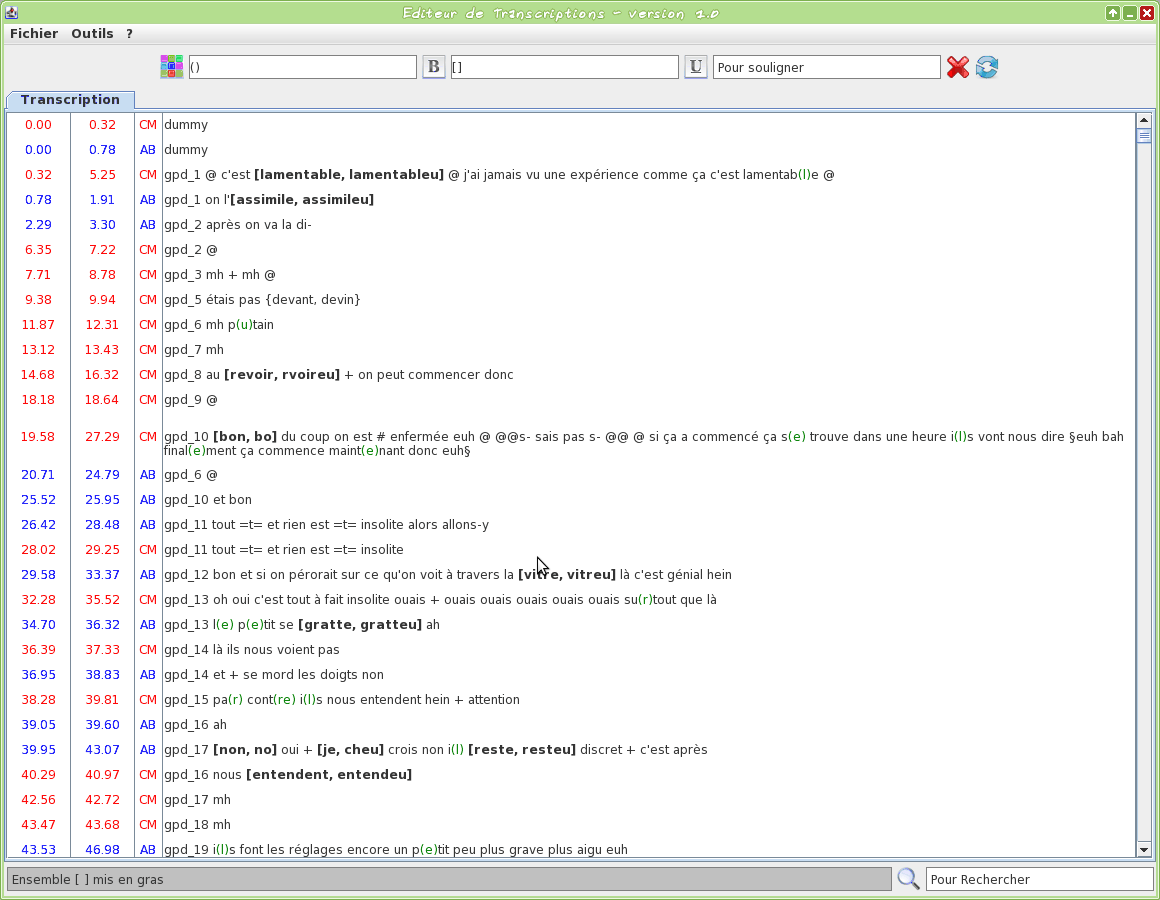
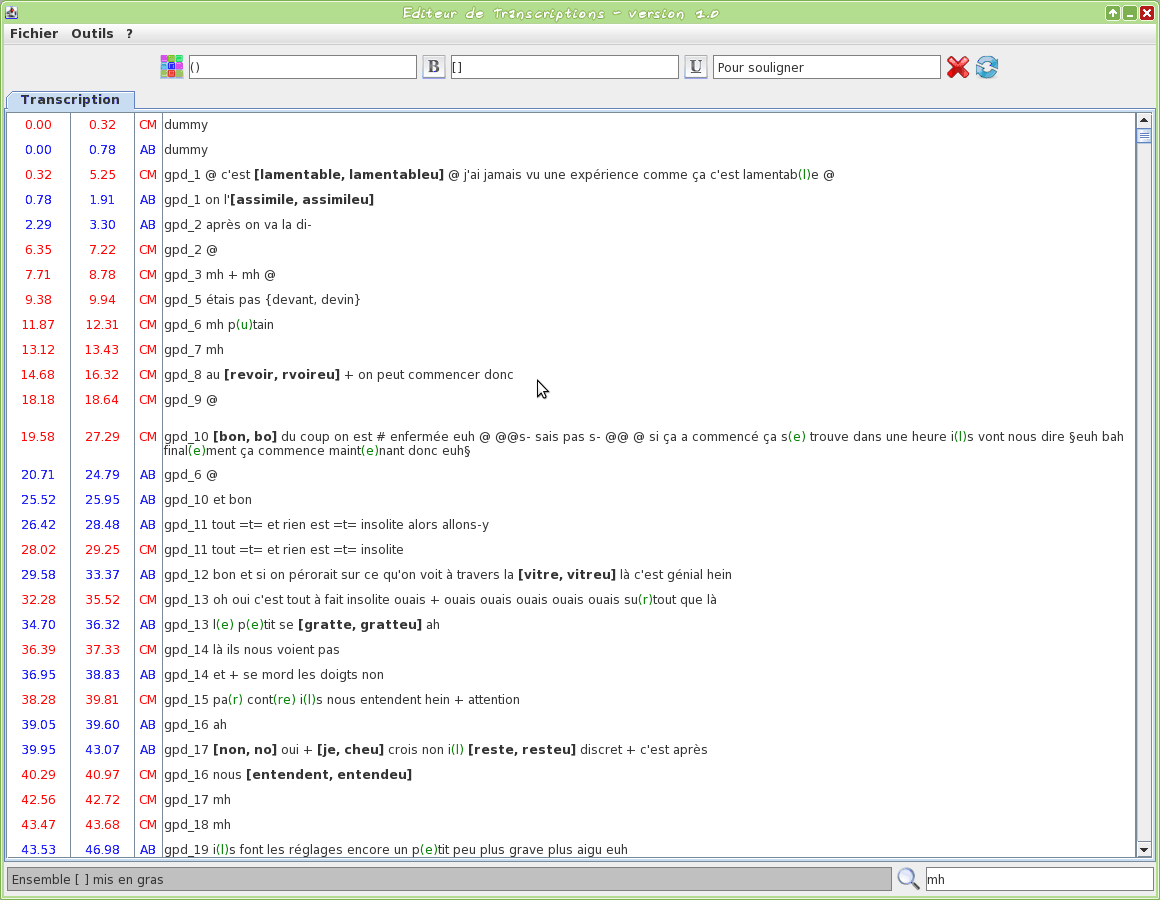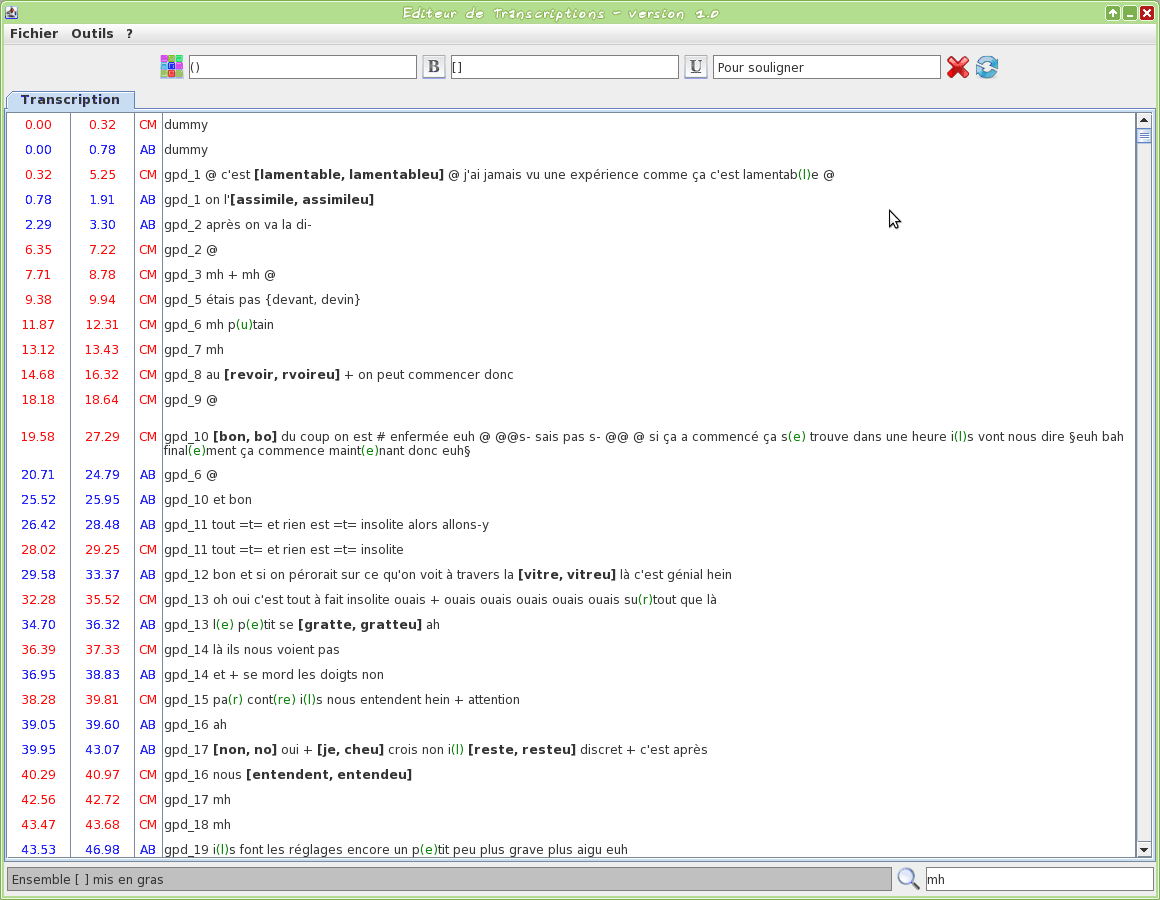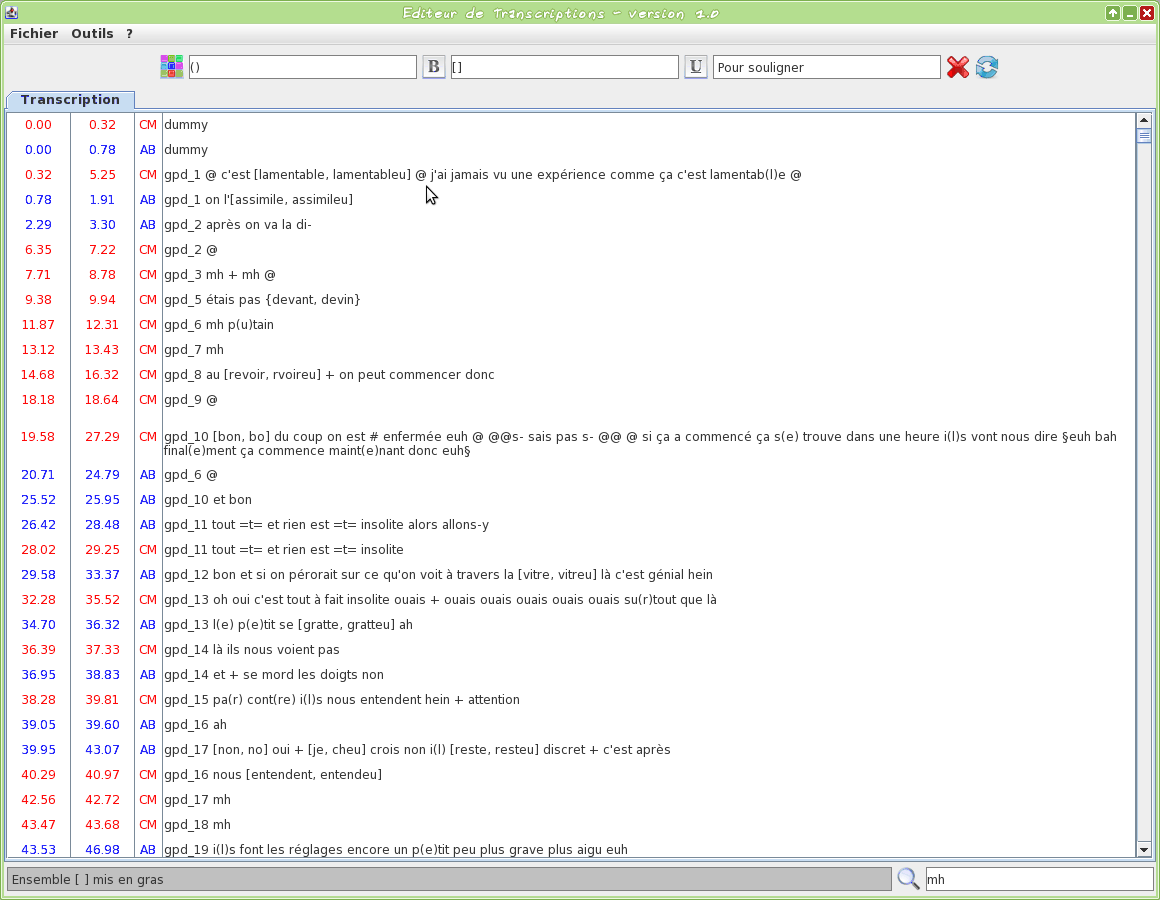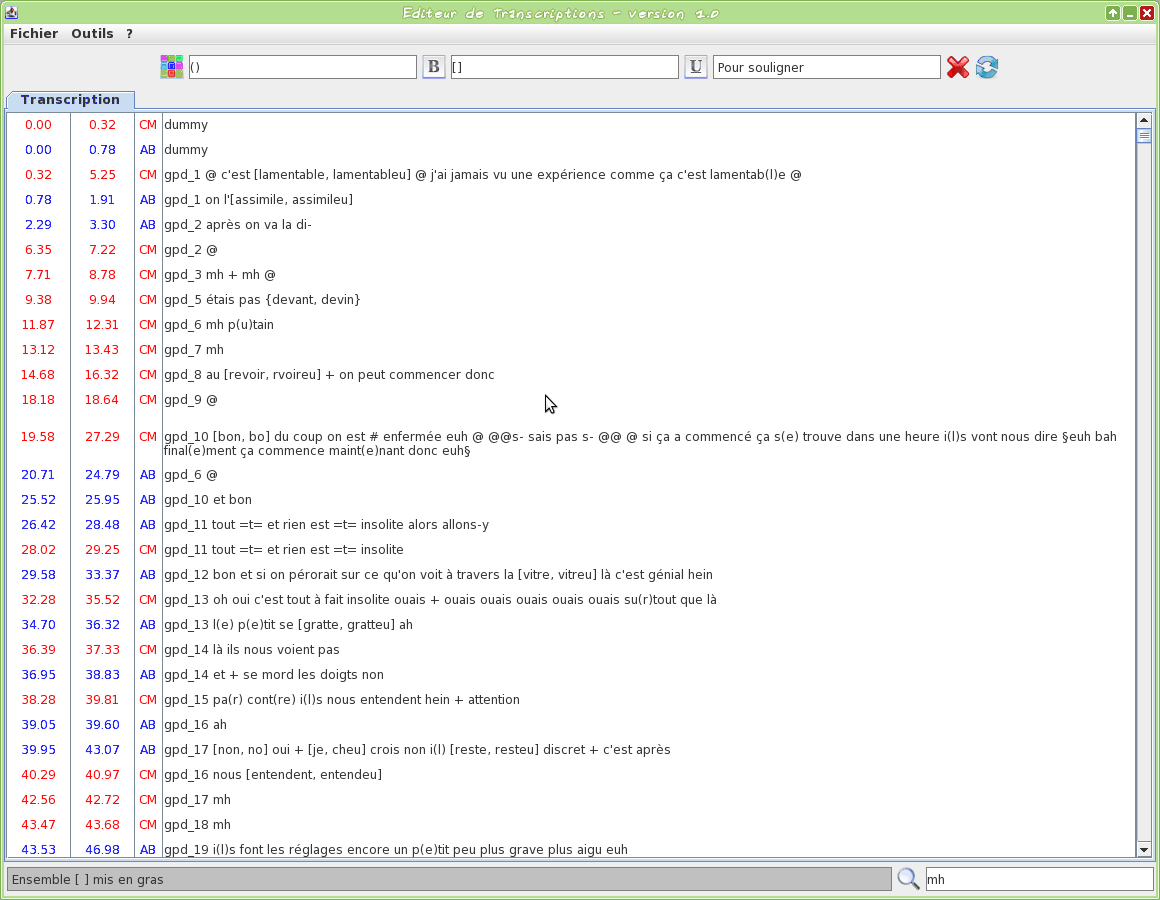
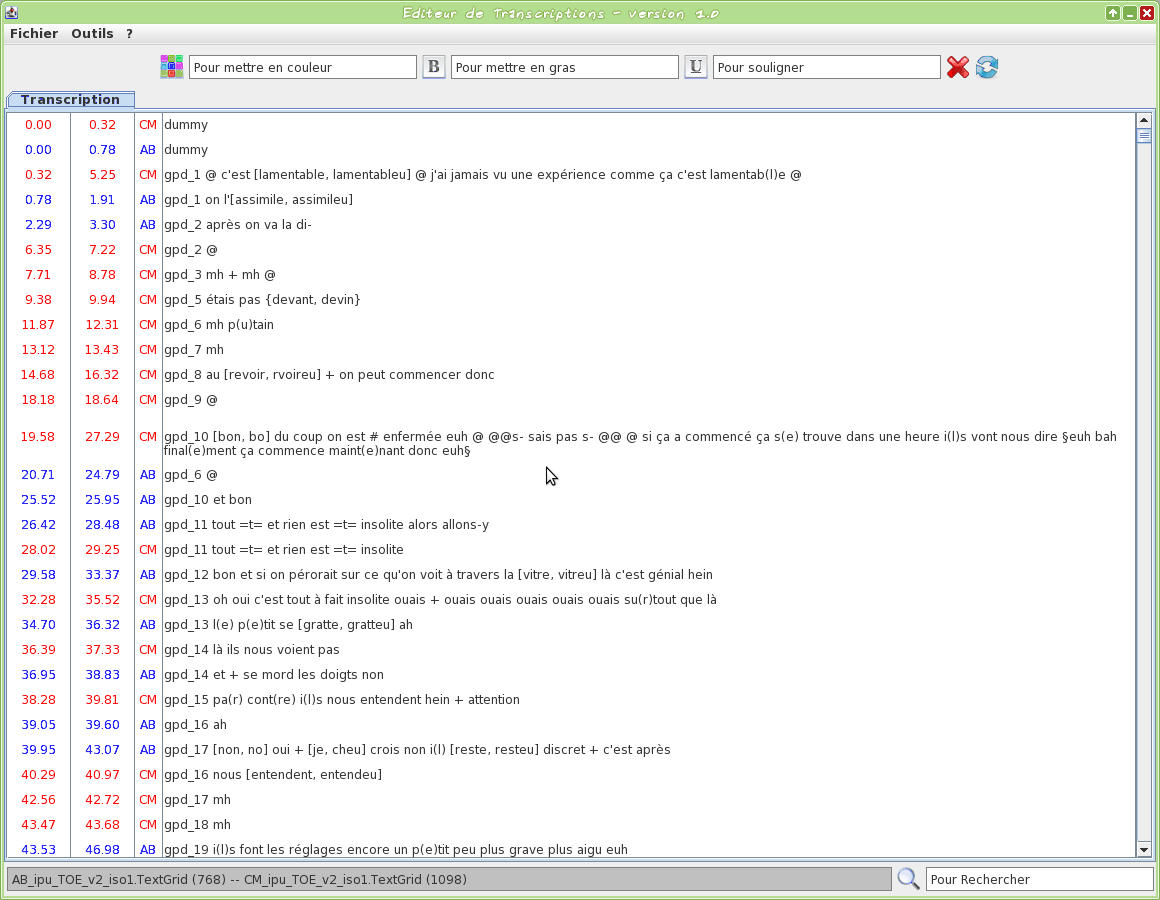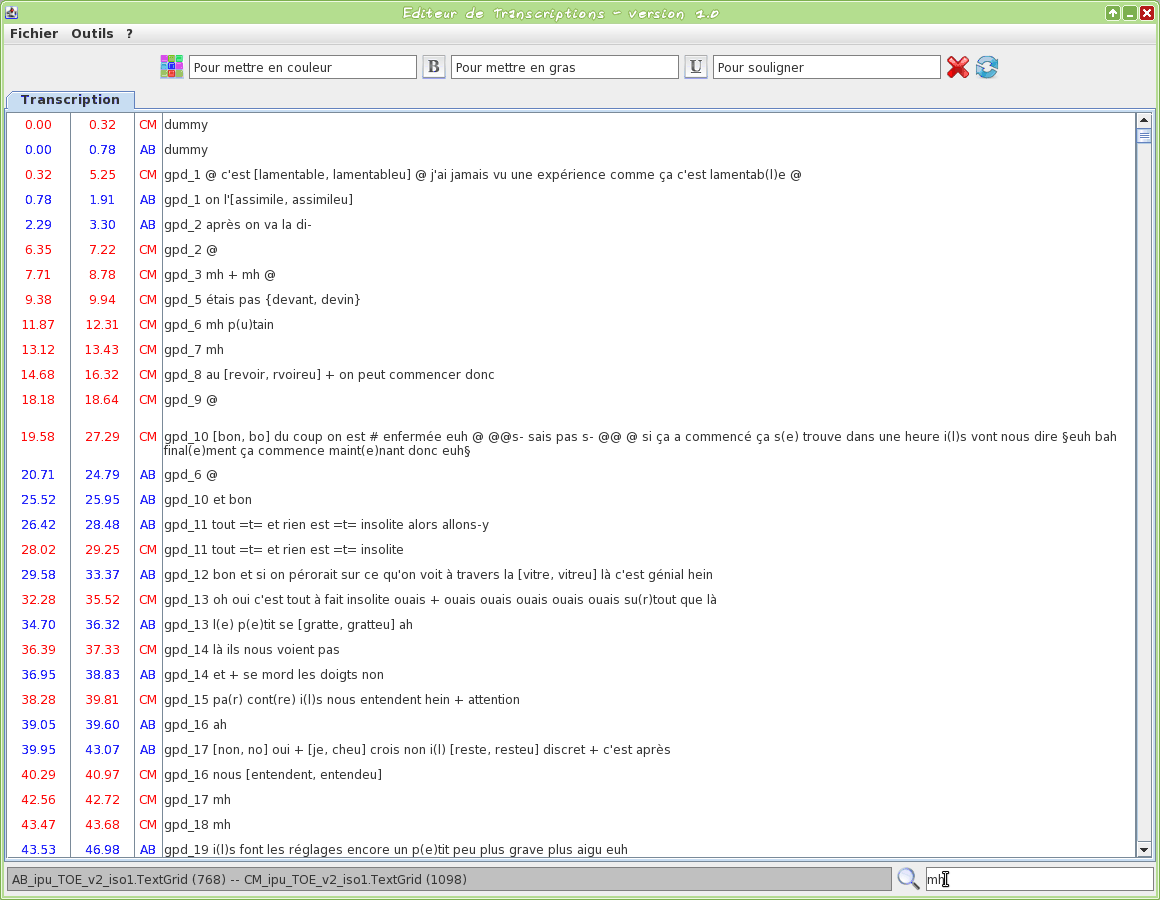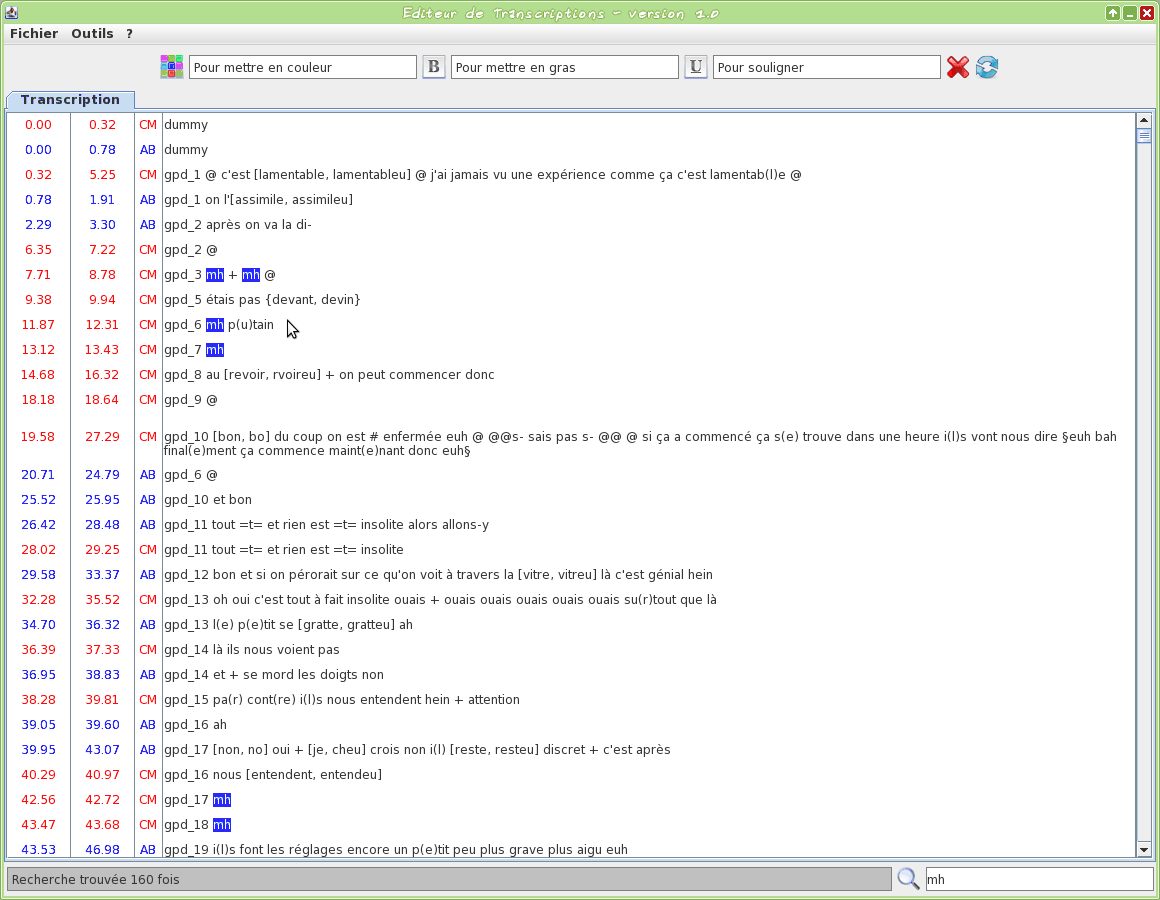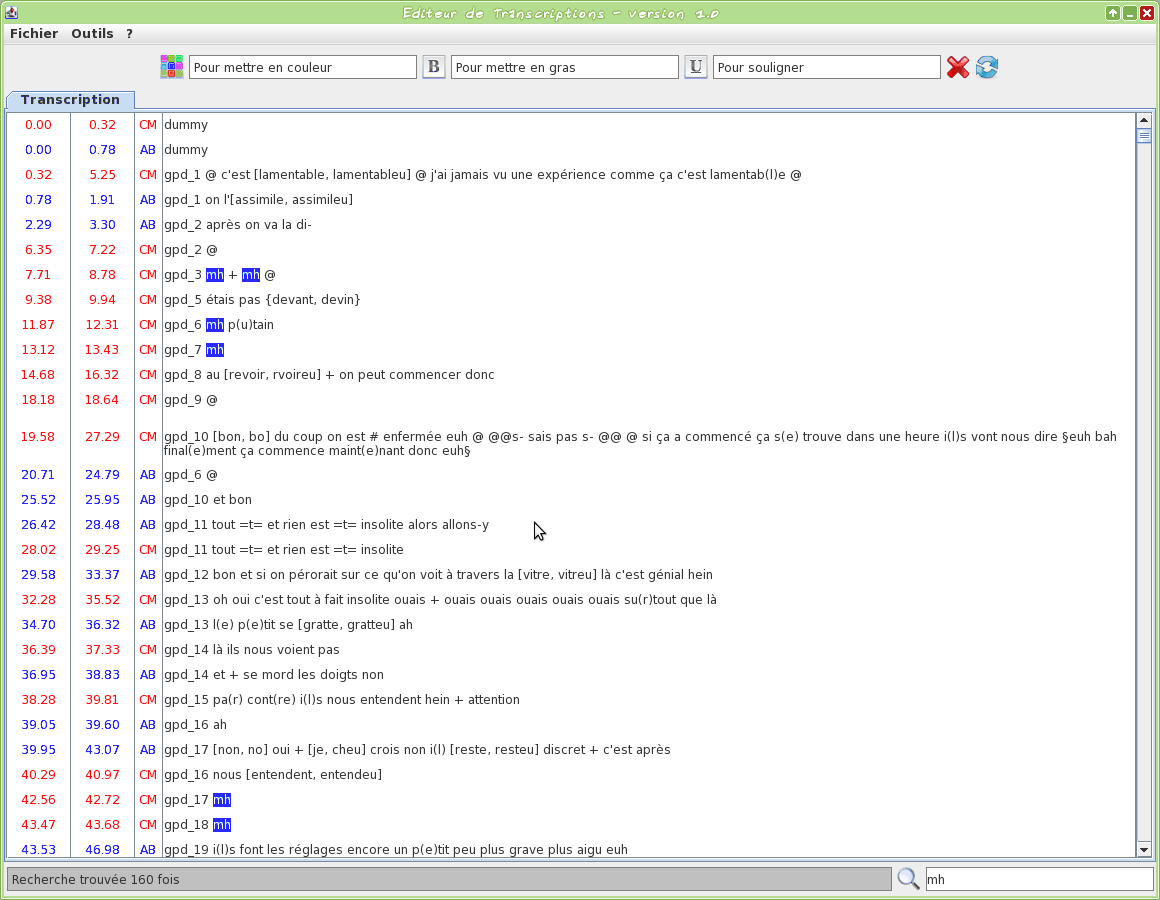
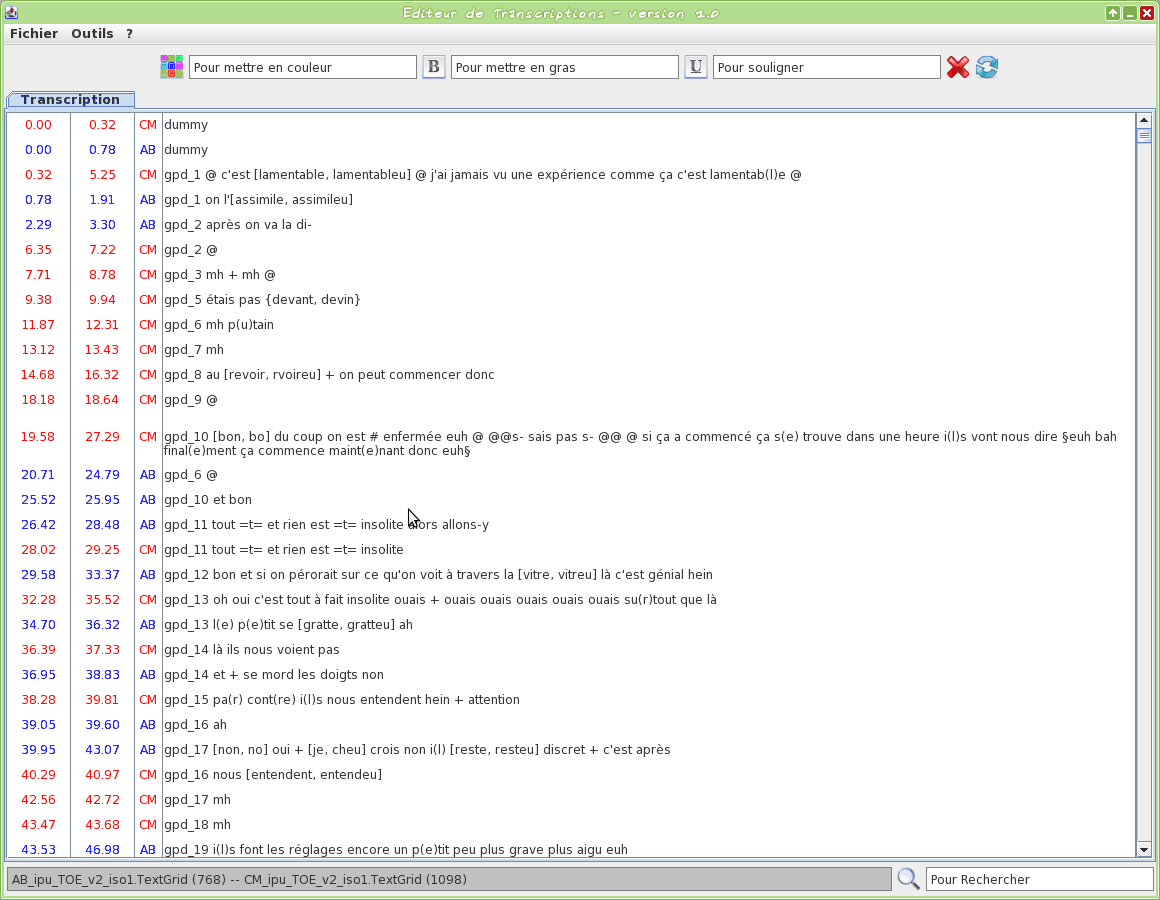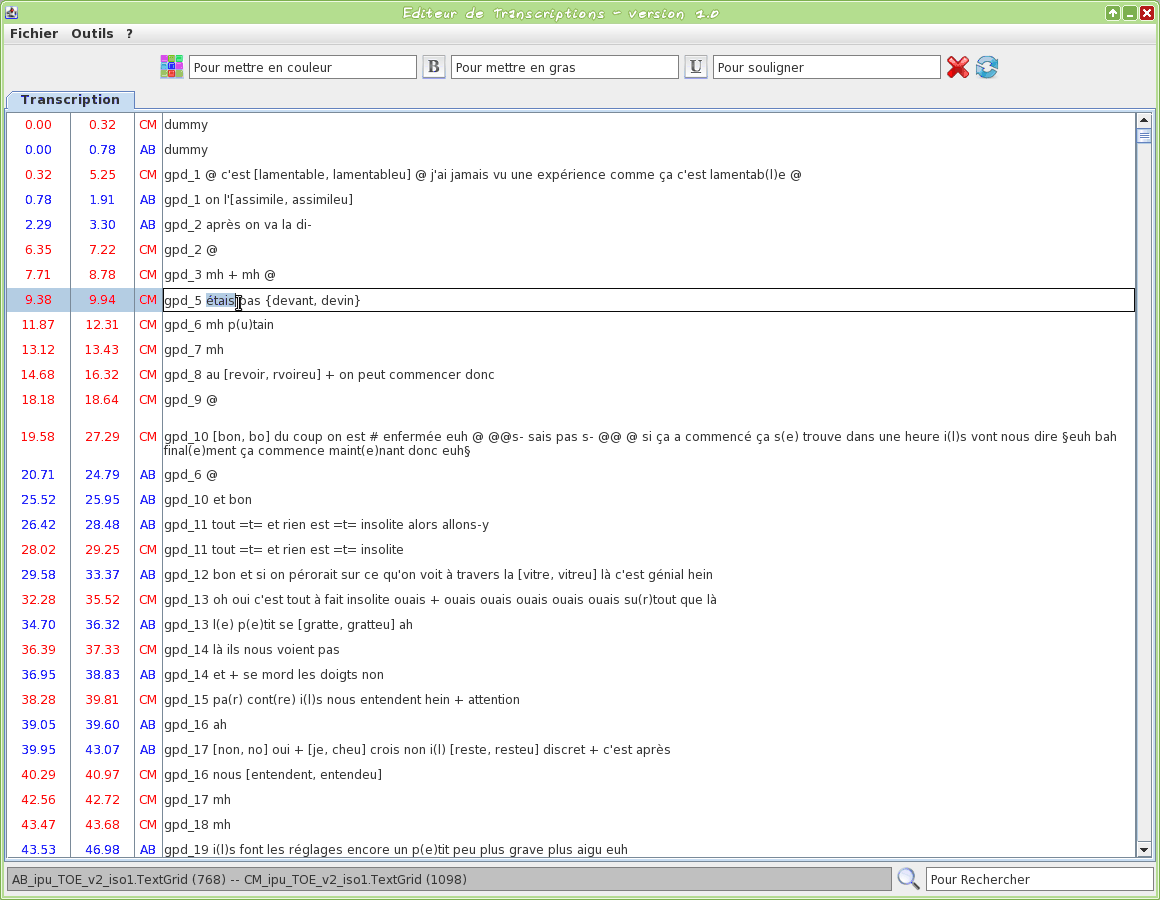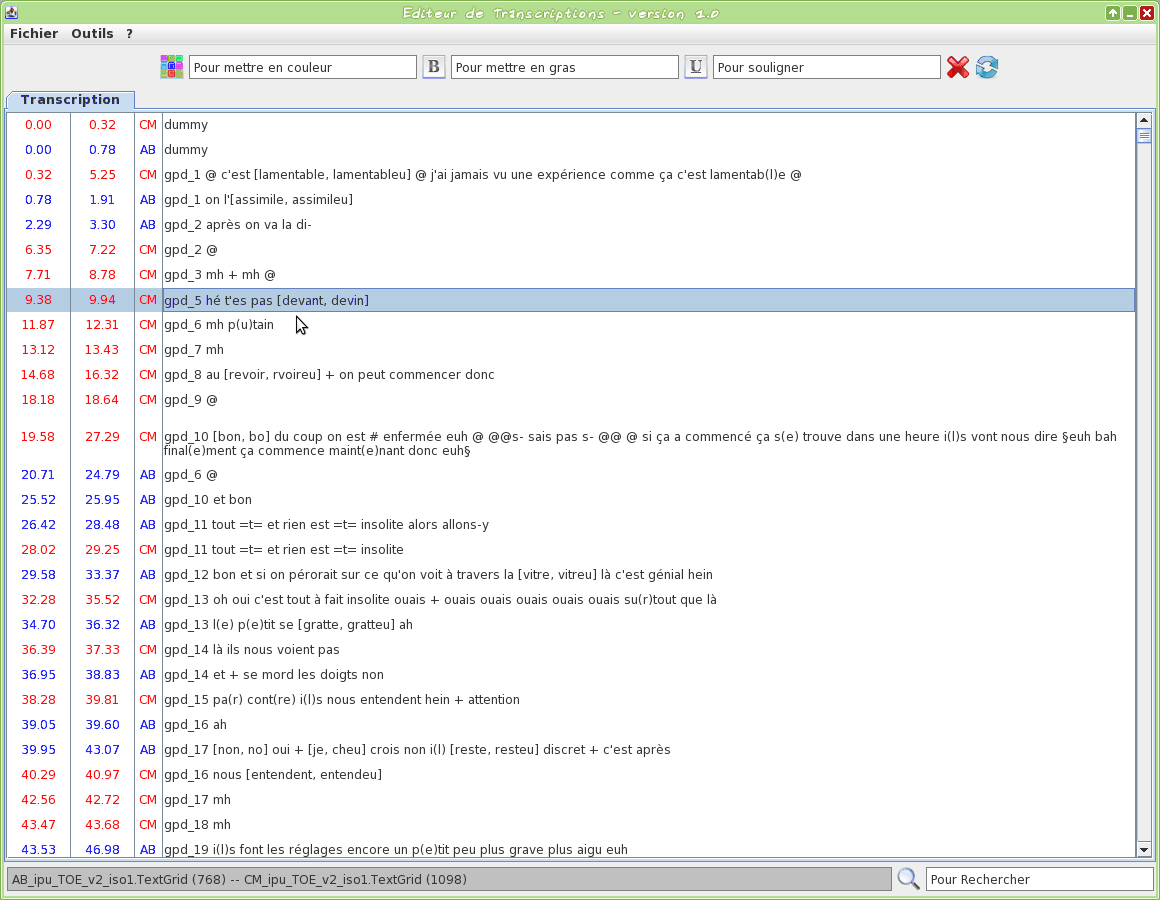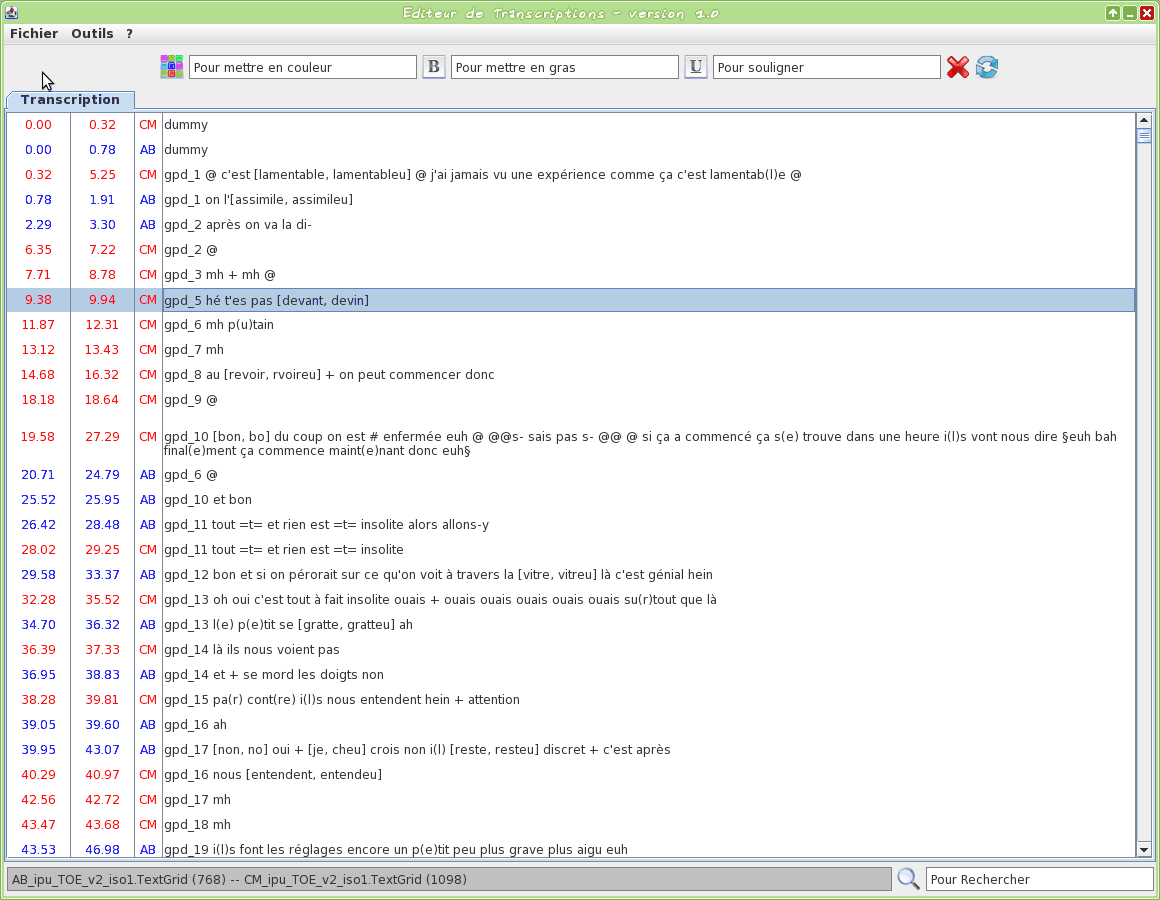
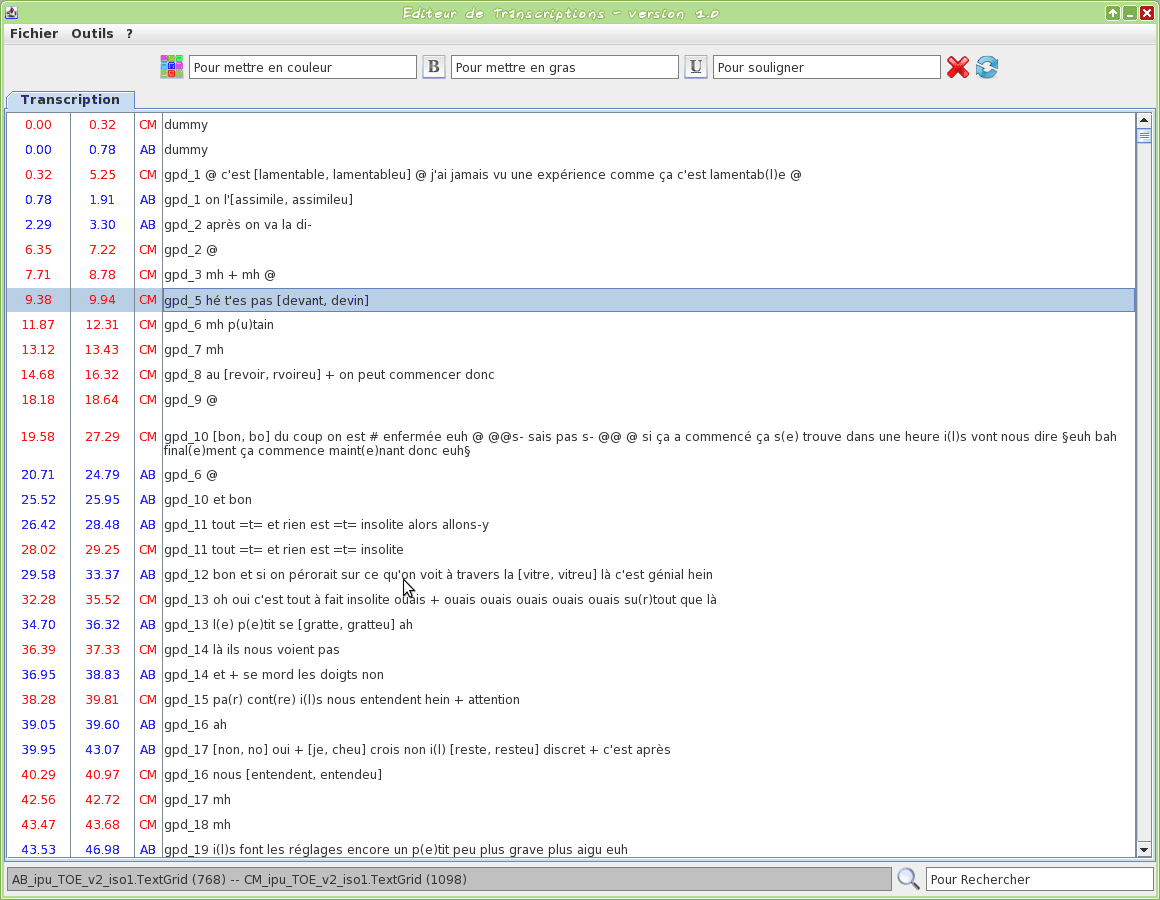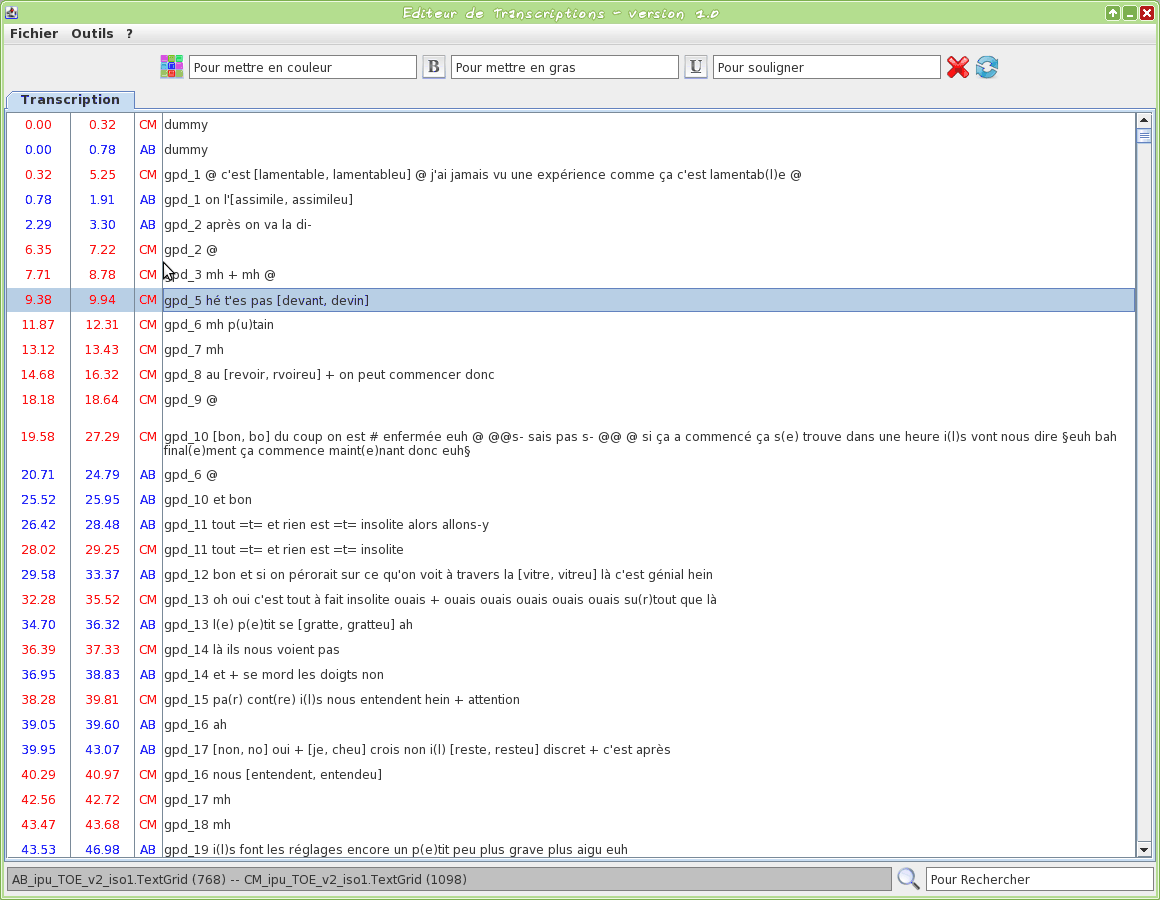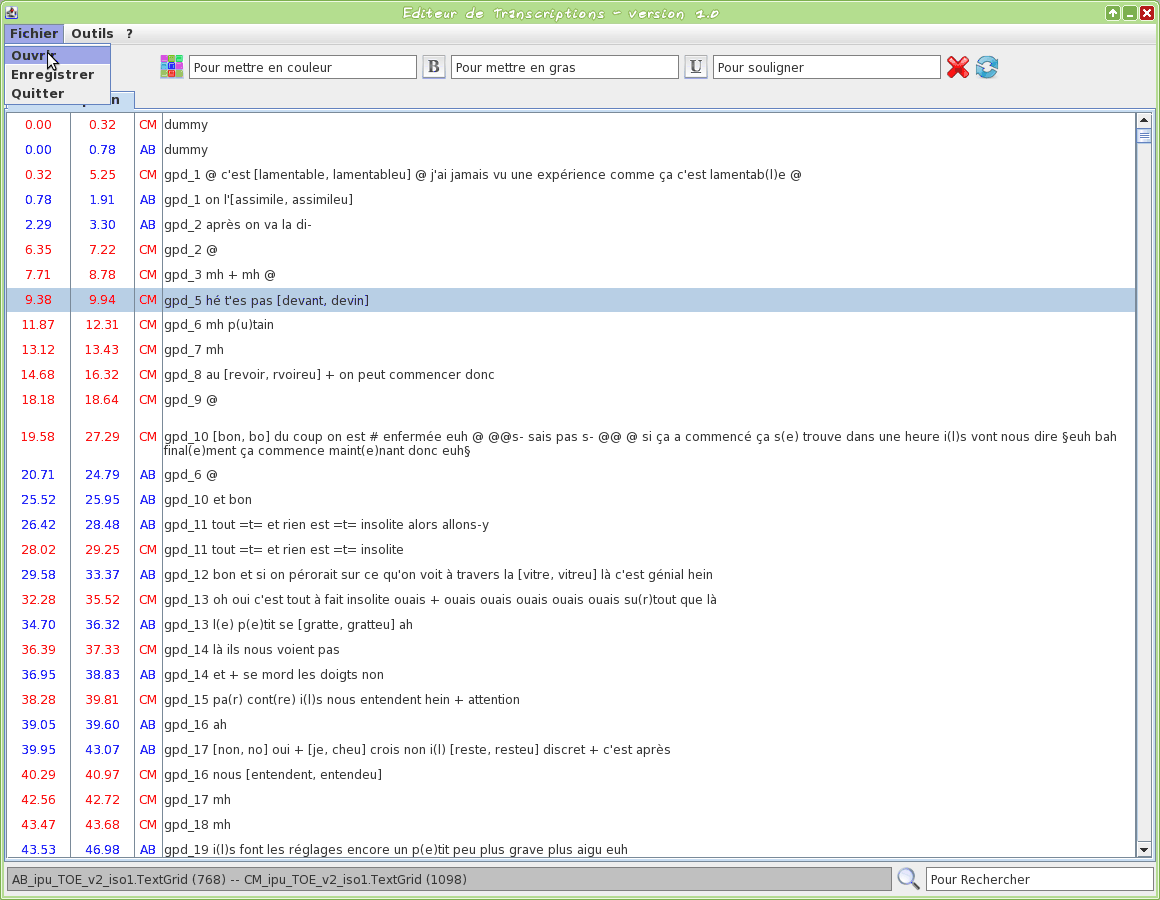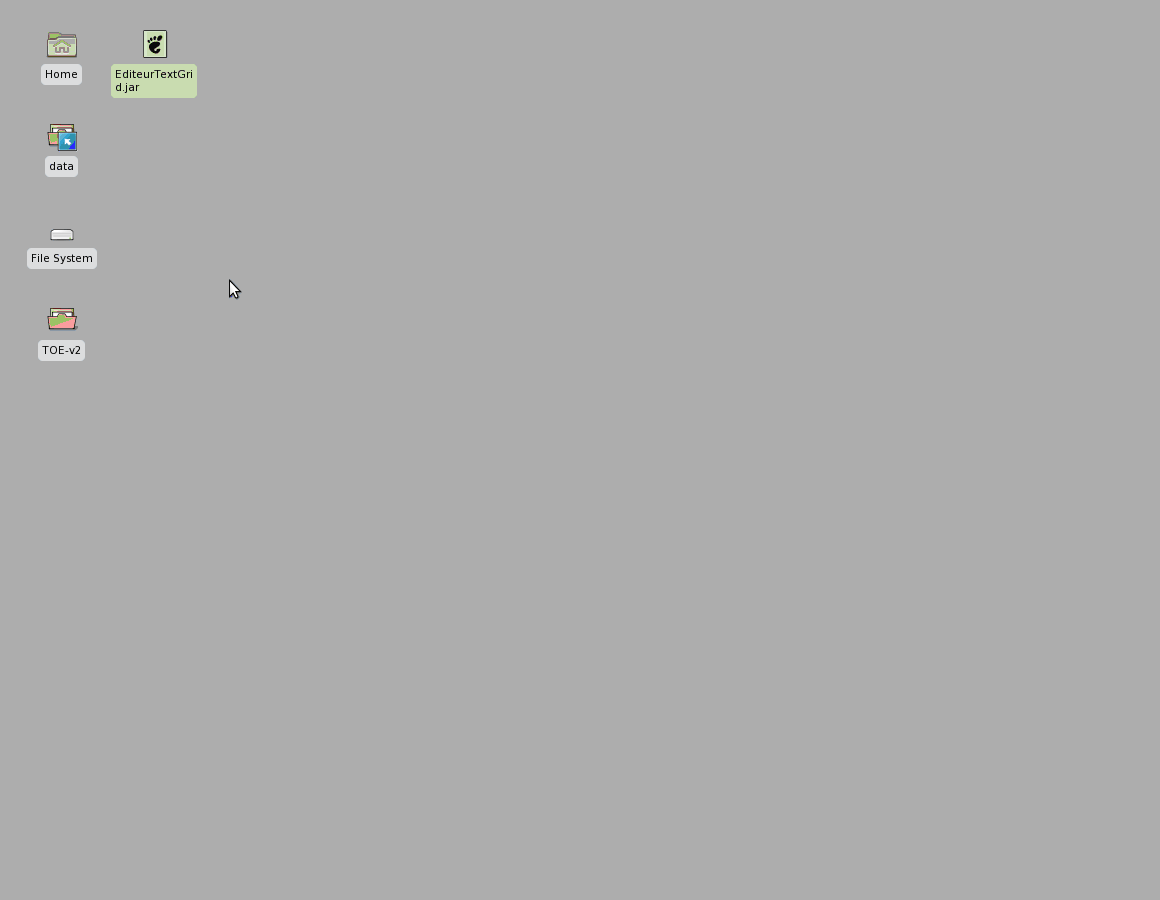
Graphical tool to edit a TextGrid transcription file
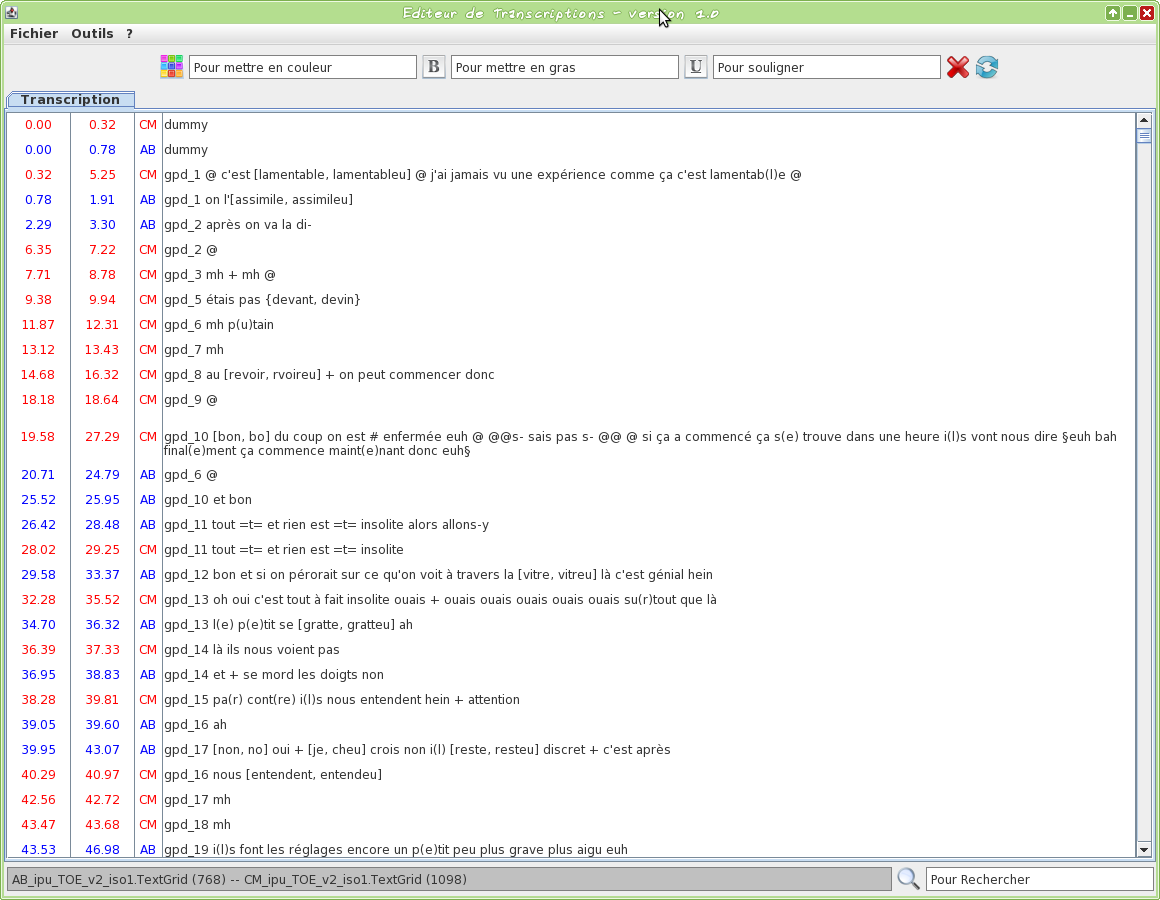
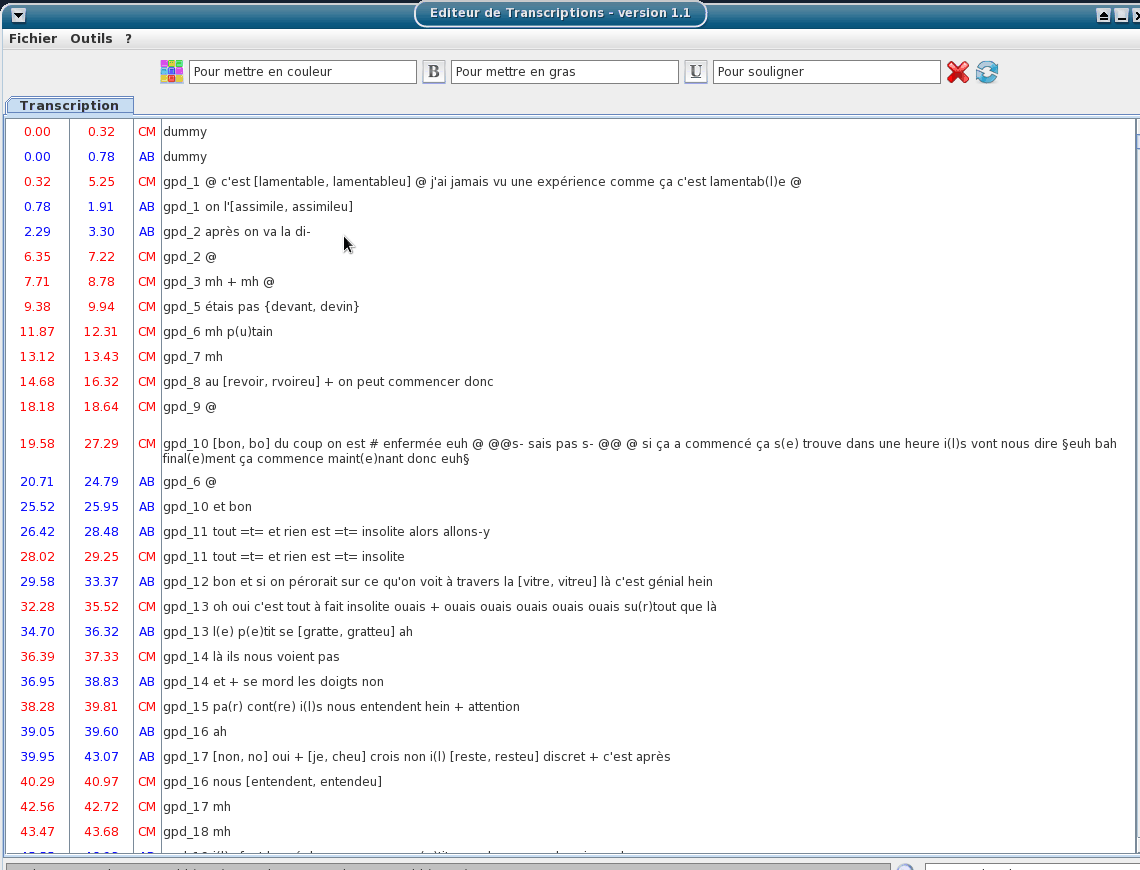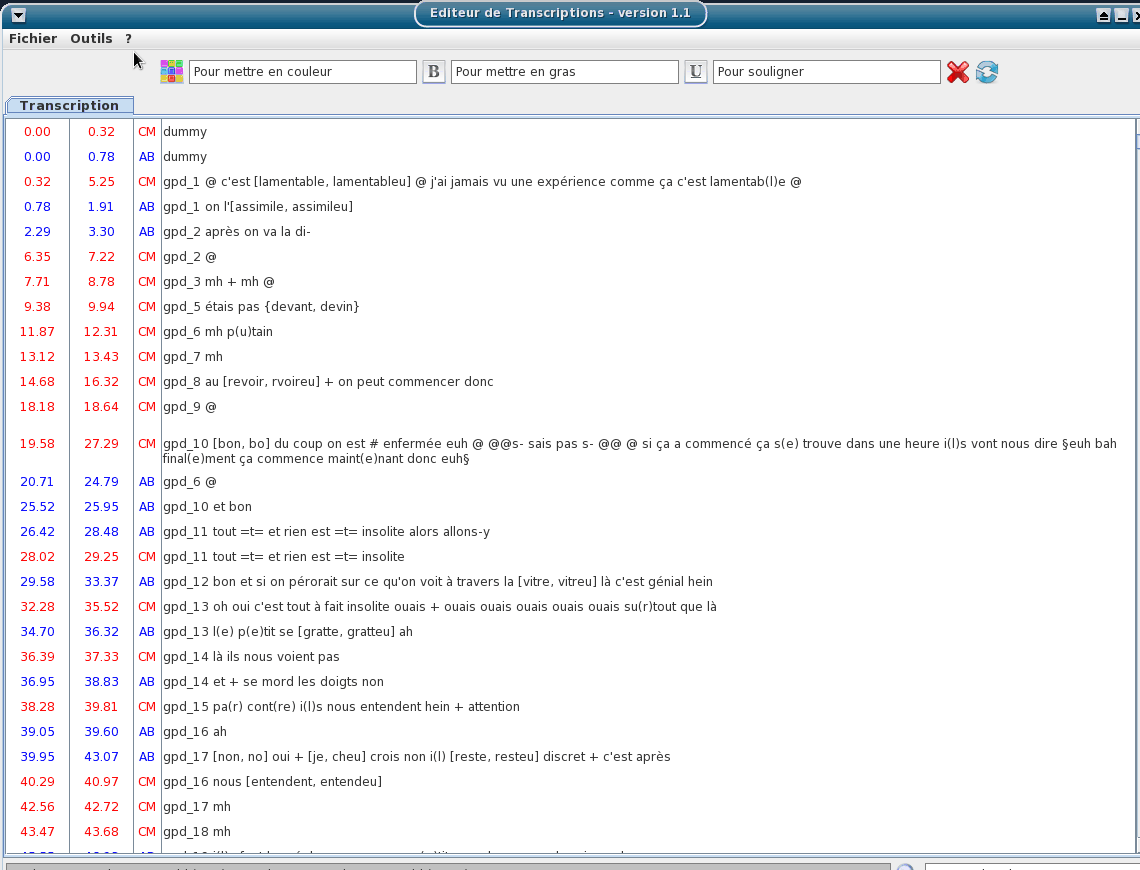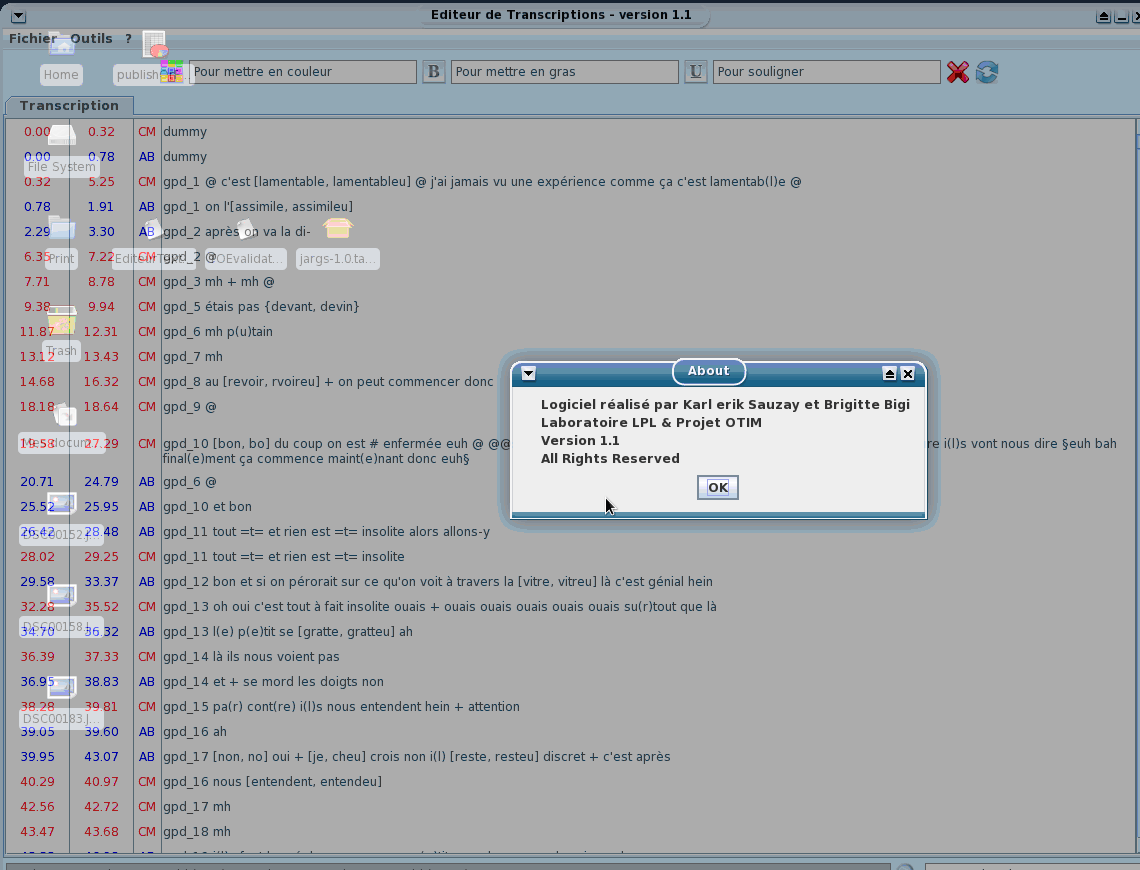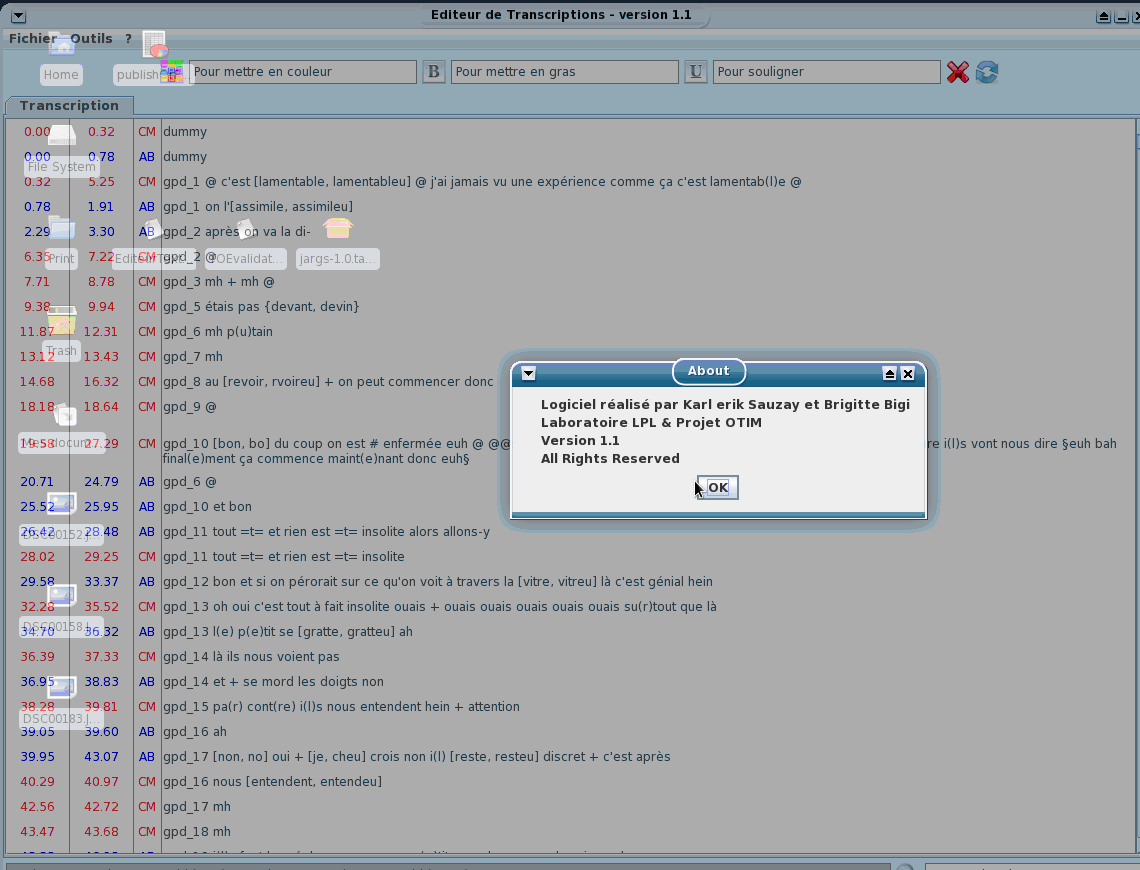
This tool is an editor specifically dedicated to transcriptions. Some TOE-specific syntax hilighting are proposed. One or two TextGrid files can be opened at the same time.
This tool is compatible with java more or equal 1.5.
The input transcription files are TextGrid (only the first tier is visible).
The firsts two letters of the filename will be used to assign a name to the speaker.
Version 1.0 screencasts:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Download the EditeurTextGrid-1.0.jar
Version 1.1:
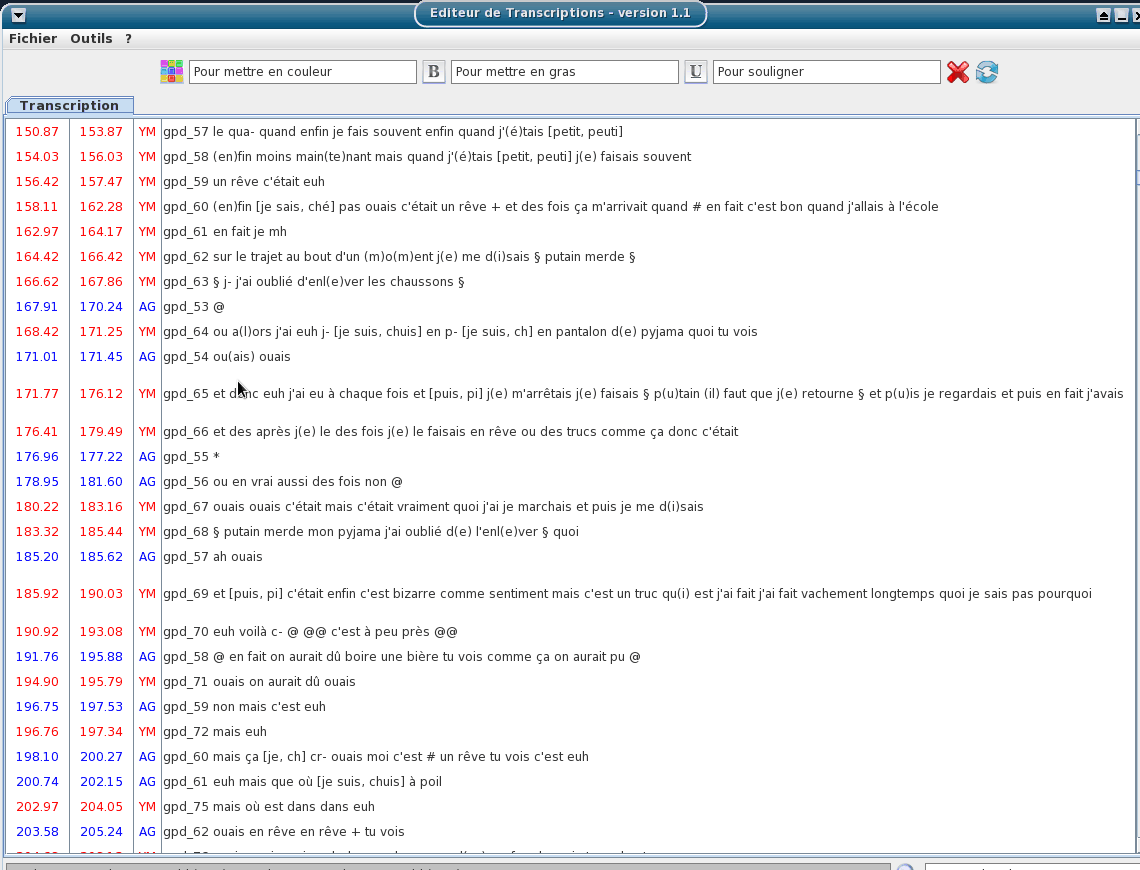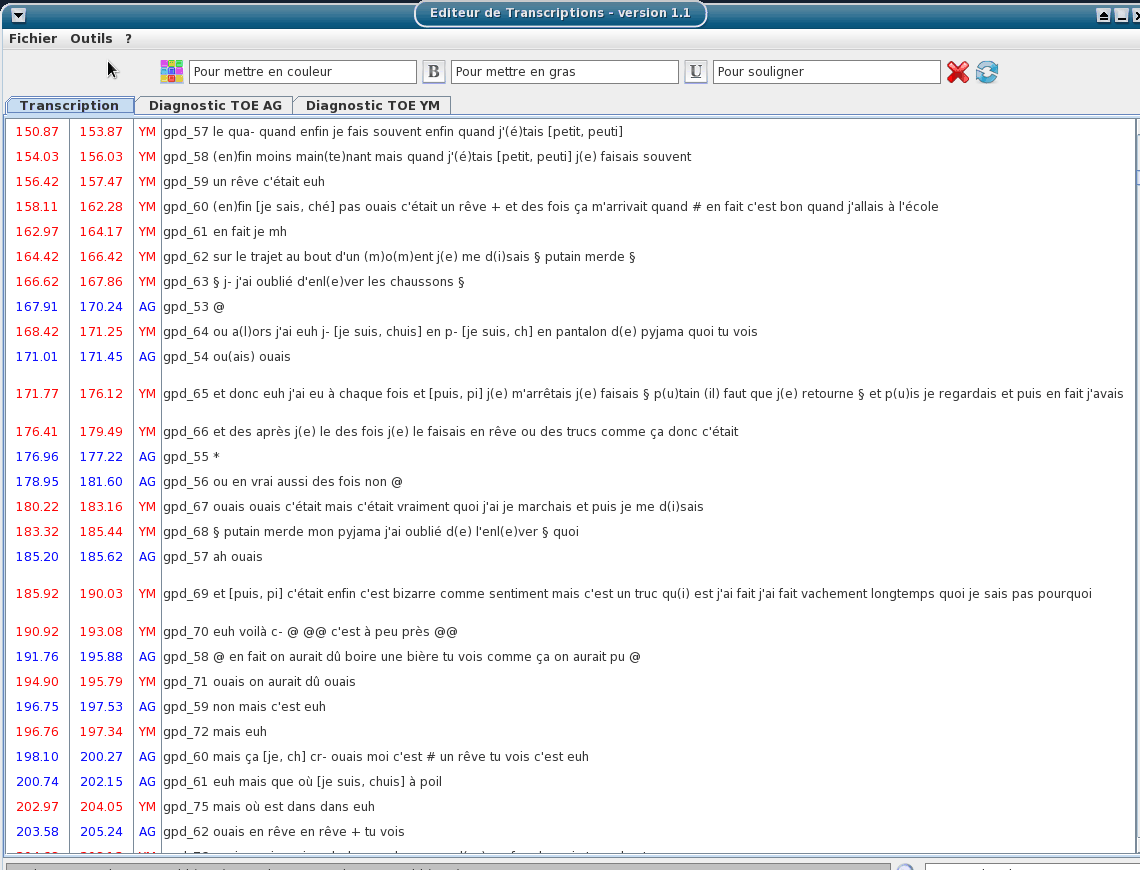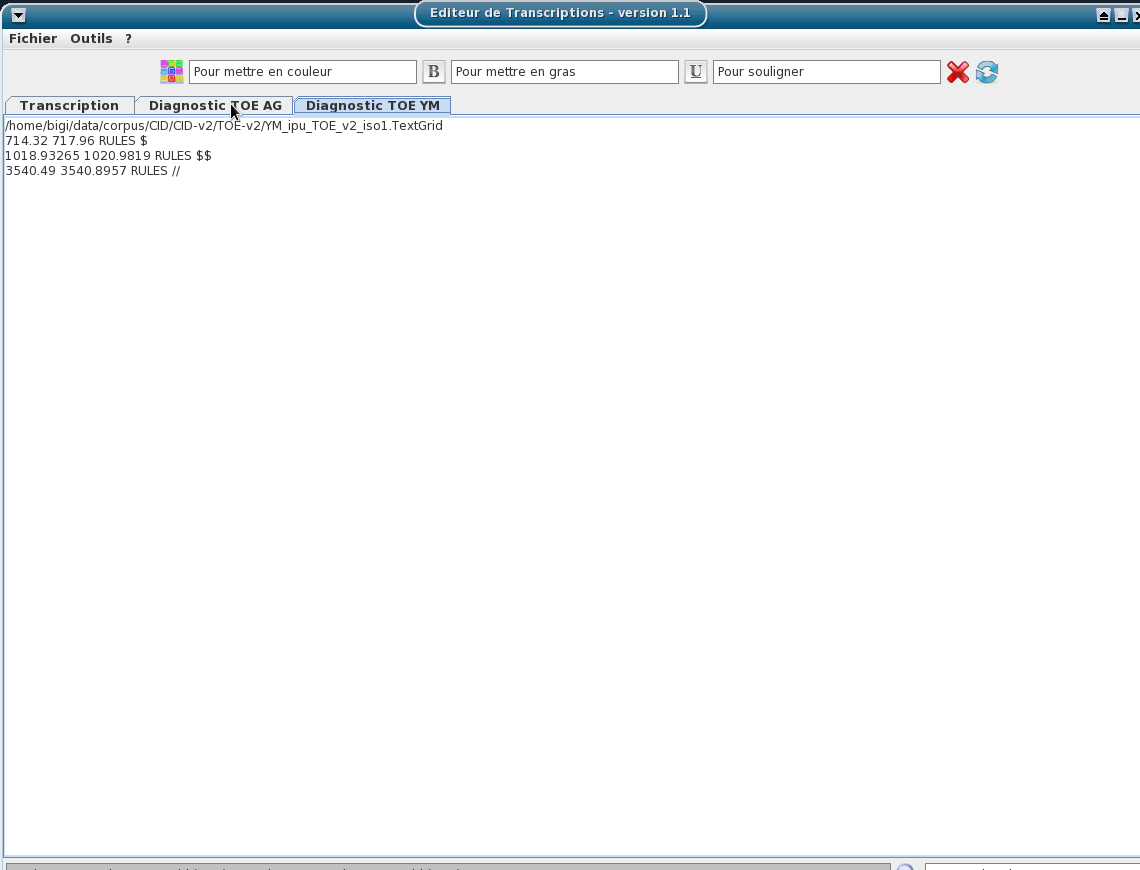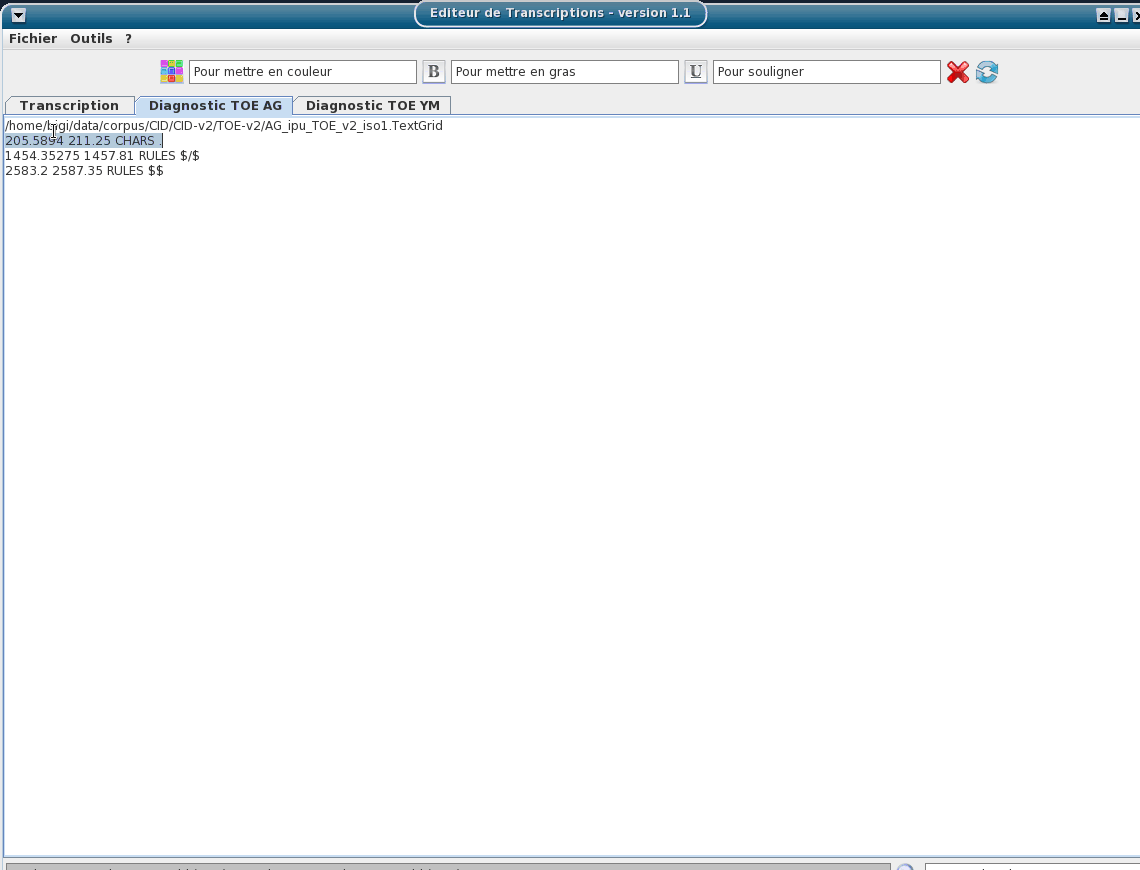
Include a TOE-validator option: a diagnostic tool to verify if the TOE syntax of the opened textgrid files is valid.
{kind=link}
{kind=link}
Download the EditeurTextGrid-1.1.jar
SPPAS: a tool to perform phonetic segmentations
SPPAS is a tool to produce automatically annotations which includes utterance, word, syllabic and phonemic segmentations from a recorded speech sound and its transcription. The whole procedure is a succession of 4 automatic steps. Resulting alignments are a set of TextGrid files. SPPAS is currently designed for French, English, Italian and Chinese and there is an easy way to add other languages. SPPAS works on Linux, MacOs and on Windows+Cygwin. SPPAS is distributed under GNU Public License.